







An SQL database must handle multiple incoming connections simultaneously to maintain optimal system performance. The expectation is that the database can accept and process numerous requests in parallel. It's straightforward when different requests target separate data, such as one request reading from Table 1 and another from Table 2. However, complications arise when multiple requests involve reading from and writing to the same table. How do we keep the performance high and yet avoid consistency issues? Let’s read on to understand how things work in SQL databases and distributed systems.
Transactions and Issues
An SQL transaction is a collection of queries (such as SELECT, INSERT, UPDATE, DELETE) sent to the database to be executed as a single unit of work. This means that either all queries in the transaction must be executed, or none should be. Executing transactions is not atomic and takes time. For example, a single UPDATE statement might modify multiple rows, and the database system needs time to update each row. During this update process, another transaction might start and attempt to read the modified rows. This raises the question: should the other transaction read the new values of the rows (even if not all rows are updated yet), the old values of the rows (even if some rows have been updated), or should it wait? What happens if the first transaction must be canceled later for any reason? How should this affect the other transaction?
ACID
Transactions in SQL databases must adhere to ACID. They must be:
Atomic - each transaction is either completed or reverted entirely. The transaction can’t modify only some records and fail for others.
Consistent - modified entities must still meet all the consistency requirements. Foreign keys must point to existing entities, values must meet the data type specifications, and other checks must still pass.
Isolated - transactions must interact with each other following the isolation levels they specified.
Durable - when the transaction is confirmed to be committed, the changes must be persistent even in the face of software issues and hardware failures.
Before explaining what isolation levels are, we need to understand what issues we may face in SQL databases (and distributed systems in general).
Read Phenomena
Depending on how we control concurrency in the database, different read phenomena may appear. The standard SQL 92 defines three read phenomena describing various issues that may happen when two transactions are executed concurrently with no transaction isolation in place.
We’ll use the following People table for the examples:
id | name | salary |
1 | John | 150 |
2 | Jack | 200 |
Dirty Read
When two transactions access the same data and we allow for reading values that are not yet committed, we may get a dirty read. Let’s say that we have two transactions doing the following:
Transaction 1 | Transaction 2 |
UPDATE People SET salary = 180 WHERE id = 1 | |
SELECT salary FROM People WHERE id = 1 | |
ROLLBACK |
Transaction 2 modifies the row with id = 1, then Transaction 1 reads the row and gets a value of 180, and Transaction 2 rolls things back. Effectively, Transaction 1 uses values that don’t exist in the database. What we would expect here is that Transaction 1 uses values that were successfully committed in the database at some point in time.
Repeatable Read
Repeatable read is a problem when a transaction reads the same thing twice and gets different results each time. Let’s say the transactions do the following:
Transaction 1 | Transaction 2 |
SELECT salary FROM People WHERE id = 1 | |
UPDATE People SET salary = 180 WHERE id = 1 | |
COMMIT | |
SELECT salary FROM People WHERE id = 1 |
Transaction 1 reads a row and gets a value of 150. Transaction 2 modifies the same row. Then Transaction 1 reads the row again and gets a different value (180 this time).
What we would expect here is to read the same value twice.
Phantom Read
Phantom read is a case when a transaction looks for rows the same way twice but gets different results. Let’s take the following:
Transaction 1 | Transaction 2 |
SELECT * FROM People WHERE salary < 250 | |
INSERT INTO People(id, name, salary) VALUES (3, Jacob, 120) | |
COMMIT | |
SELECT * FROM People WHERE salary < 250 |
Transaction 1 reads rows and finds two of them matching the conditions. Transaction 2 adds another row that matches the conditions used by Transaction 1. When Transaction 1 reads again, it gets a different set of rows. We would expect to get the same rows for both SELECT statements of Transaction 1.
Consistency Issues
Apart from read phenomena, we may face other problems that are not defined in the SQL standard and are often neglected in the SQL world. However, they are very common once we scale out the database or start using read replicas. They are all related to the consistency models which we will cover later on.
Dirty Writes
Two transactions may modify elements independently which may lead to a situation in which the outcome is inconsistent with any of the transactions.
Transaction 1 | Transaction 2 |
UPDATE People SET salary = 180 WHERE id = 1 | |
UPDATE People SET salary = 130 WHERE id = 1 | |
UPDATE People SET salary = 230 WHERE id = 2 | |
COMMIT | |
UPDATE People SET salary = 280 WHERE id = 2 | |
COMMIT |
After executing the transactions, we end with values 130 and 280 which are inconsistent and don’t come from any of the transactions.
Old Versions
A read transaction may return any value that was written in the past but is not the latest value.
Transaction 1 | Transaction 2 | Transaction 3 |
UPDATE People SET salary = 180 WHERE id = 1 | ||
COMMIT | ||
SELECT * FROM People WHERE id = 1 | ||
SELECT * FROM People WHERE id = 1 |
In this example, Transaction 2 and Transaction 3 may be issued against secondary nodes of the system that may not have the latest changes. If that’s the case, then Transaction 2 may return any of 150 and 180. The same goes for Transaction 3. It’s perfectly valid for Transaction 2 to return 180 (which is expected) and then Transaction 3 may read 150.
Delayed Writes
Imagine that we have the following transactions:
Client 1 Transaction 1 |
UPDATE People SET salary = 180 WHERE id = 1 |
COMMIT |
Client 1 Transaction 2 |
SELECT * FROM People WHERE id = 1 |
We would expect Transaction 2 to return the value that we wrote in the previous transaction, so Transaction 2 should return 180. However, Transaction 2 may be triggered against a read replica of the main database. If we don’t have the Read Your Writes property, then the transaction may return 150.
Non-Monotonic Reads
Another issue we may have is around the freshness of the data. Let’s take the following example:
Client 1 Transaction 1 |
UPDATE People SET salary = 180 WHERE id = 1 |
COMMIT |
Client 1 Transaction 2 |
SELECT * FROM People WHERE id = 1 |
Client 1 Transaction 3 |
SELECT * FROM People WHERE id = 1 |
Transaction 2 may return the latest value (which is 180 in this case), and then Transaction 3 may return some older value (in this case 150).
Transaction Isolation Levels
To battle the read phenomena, the SQL 92 standard defines various isolation levels that define which read phenomena can occur.
There are 4 standard levels: READ UNCOMMITED, READ COMMITED, REPEATABLE READ, and SERIALIZABLE.
READ UNCOMMITED allows a transaction to read data that is not yet committed to the database. This allows for the highest performance but it also leads to the most undesired read phenomena.
READ COMMITTED allows a transaction to read only the data that is committed. This avoids the issue of reading data that “later disappears” but doesn’t protect it from other read phenomena.
REPEATABLE READ level tries to avoid the issue of reading data twice and getting different results.
Finally, SERIALIZABLE tries to avoid all read phenomena.
The following table shows which phenomena are allowed:
Level \ Phenomena | Dirty Read | Repeatable read | Phantom |
READ UNCOMMITTED | + | + | + |
READ COMMITTED | - | + | + |
REPEATABLE READ | - | - | + |
SERIALIZABLE | - | - | - |
The isolation level is defined per transaction. For example, it’s allowed for one transaction to run with a SERIALIZALBLE level, and for another to run with READ UNCOMMITED.
Interestingly, there is no requirement for various isolation levels to be implemented in an SQL database. It is acceptable if all isolation levels are implemented as SERIALIZABLE.
The isolation levels protect us from some of the issues described earlier. Before moving on, we need to understand how they are implemented.
Locks and Latches and Deadlock Detection
Locks are synchronization mechanisms used to protect shared memory from corruption, as atomic operations are not possible. To understand this in practice, consider how CPUs interact with memory, which is divided into cells of various sizes.
CPU Internals
A typical CPU can access a fixed-size memory cell, often referred to as an "int." The size of these cells depends on the CPU architecture and the specific operation, with some CPUs handling as little as 8 bits and others up to 512 bits simultaneously. Most modern CPUs, like the widely-used Intel 64 architecture, operate with a native data size of 64 bits, using 64-bit long registers for most operations.
Practically, this means a CPU cannot write more than 64 bits in a single operation. Writing 512 bits, for example, requires eight separate writes. While some CPUs can perform these writes in parallel, they usually execute them sequentially. This limitation becomes significant when modifying data structures larger than 64 bits, as the CPU cannot update them in a single time slice. With multi-core CPUs, another core might start reading the structure before it is fully modified, risking data corruption. To prevent this, we need to mark the structure as "unavailable" to other CPU cores until the modification is complete. This is where locks come in.
In the context of SQL, memory structures like tables, rows, pages, and the database itself are often much larger than 64 bits. Furthermore, a single SQL operation may update multiple rows at once, which exceeds the CPU's capacity for a single operation. Hence, locks are necessary to ensure data modification occurs without compromising data consistency.
Locks
The types of locks available depend on the SQL engine in use, but many databases adopt a similar approach.
Each lock can be acquired with a specific mode that dictates what other transactions are allowed to do with the lock. Some common lock modes are:
Exclusive - Only the transaction that acquires the lock can use it, preventing other transactions from acquiring the lock. Used when modifying data (DELETE, INSERT, UPDATE). Typically acquired at the page or row level.
Shared - A read lock that allows multiple transactions to acquire it for reading data. Often used as a preliminary step before converting to a lock that permits modifications.
Update - Indicates an upcoming update. Once the owner is ready to modify the data, the lock is converted to an Exclusive lock.
Intent Lock - Indicates a lock on a subpart of the locked structure. For example, an intent lock on a table suggests that a row in this table will also be locked. Prevents others from taking exclusive locks on the structure. For example, if transaction A wants to modify a row in a table, it takes an exclusive lock on the row. If transaction B then wants to modify multiple rows and takes an exclusive lock on the table, a conflict arises. An intent lock on the table alerts transaction B that there's already an ongoing lock within the table, avoiding such conflicts. Types of intent locks include intent exclusive, intent shared, intent update, shared with intent exclusive, shared with intent update, and update with intent exclusive.
Schema - Locks for schema modifications. To prepare for a schema change, the SQL engine needs time, so other transactions must be prevented from modifying the schema, though they can still read or change data.
Bulk Update - A lock used for bulk import operations.
Locks can be applied to various objects in the hierarchy:
Database - Typically involves a shared lock.
Table - Usually takes an intent lock or exclusive lock.
Page - A group of rows of fixed size, typically taking an intent lock.
Row - Can take a shared, exclusive, or update lock.
Locks can also escalate from rows to pages to tables or be converted to different types. For more detailed information, consult your SQL engine's documentation.
Latches
In addition to logical locks that protect the actual data stored in the database, the SQL engine must also safeguard its internal data structures. These protective mechanisms are typically referred to as latches. Latches are used by the engine when reading and writing memory pages, as well as during I/O and buffer operations.
Similar to locks, latches come in various types and modes, including
Shared - Used for reading a page.
Keep - Used to keep the page in the buffer, preventing it from being disposed of.
Update - Similar to an update lock, indicating a pending update.
Exclusive - Similar to exclusive locks, preventing other latches from being acquired.
Destroy Latch - Acquired when a buffer is to be removed from the cache.
Latches are typically managed exclusively by the SQL engine (sometimes called the SQL Operating System) and cannot be modified by users. They are acquired and released automatically. However, by observing latches, users can identify where and why performance degrades
Isolation Levels
Now, let's explore how isolation levels affect lock acquisition. Different isolation levels require different types of locks.
Consider the READ COMMITTED isolation level. According to the SQL-92 standard, this level disallows only dirty reads, meaning a transaction cannot read uncommitted data. Here’s how the transaction modifies the row if it uses Strict 2-Phase Locking (for instance used by MS SQL):
The row is locked with an exclusive lock. No other transaction can now lock this row. This is Phase 1.
The data is modified.
Either the transaction is committed, or the transaction is rolled back and the row is restored to its original version.
The lock is released. This is Phase 2.
Here's how it works when scanning a table:
The first row is locked with a read lock. No other transaction can now modify the row as they can’t acquire an exclusive lock.
The data is read and processed. Since the row is protected with a lock, we are sure the data was committed at some point.
The lock is released.
The second row is locked with a read lock.
This process continues row by row.
This process guarantees that we avoid dirty reads. However, the row lock is released once a row is fully processed. This means if another transaction modifies and commits a row in between, the reading transaction will pick up the changes. This may cause duplicates when reading or even missing rows.
A typical database management system stores rows in a table in an ordered manner, often using the table's primary key within a B-tree structure. The primary key usually imposes a clustered index, causing the data to be physically ordered on the disk.
Consider a table with 10 rows, with IDs ranging from 1 to 10. If our transaction has already read the first 8 rows (IDs 1 through 8), and another transaction modifies the row with ID 2, changing its ID to 11, and commits the change, we will encounter an issue. As we continue scanning, we will now find 11 rows in total. Additionally, we'll attempt to read the row with the original ID 2, which no longer exists.
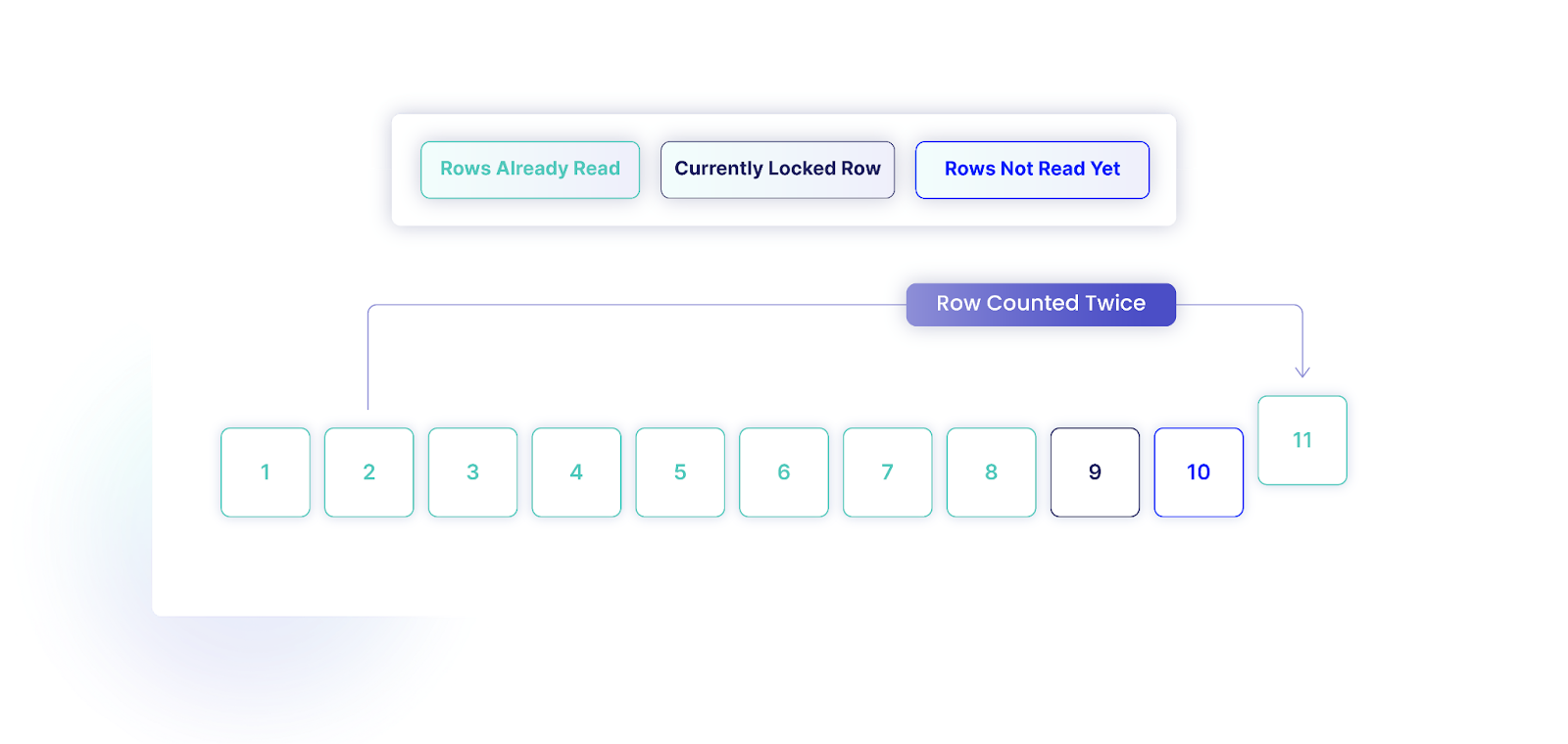
Similarly, we can miss a row due to this ordering. Imagine we have 10 rows, and we've read rows with IDs 1 to 4. If another transaction changes the row with ID 10, setting its ID to 3, our transaction will not find this row because of the reordering.
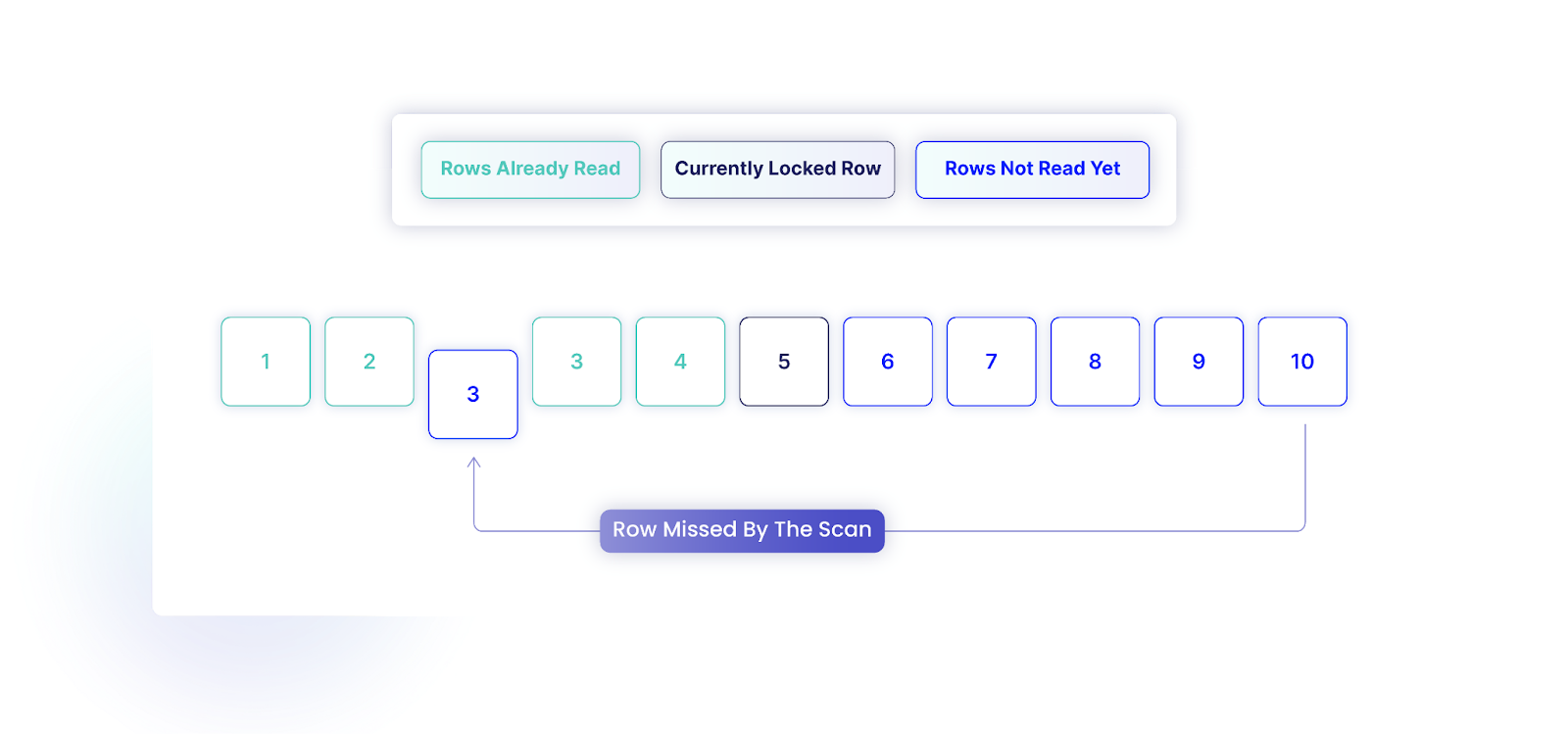
To solve this, a lock on the entire table is necessary to prevent other transactions from adding rows during the scan. When using SERIALIZABLE, the locks would be released only after the transaction and would be taken on the whole database instead of particular entities. However, this would cause all other transactions to wait until the scan is complete, which could reduce performance.
Deadlock Detection
Locks lead to deadlocks, therefore, we need a solution for understanding whether the system is deadlocked or not. There are two main approaches to deadlock detection.
The first is to monitor transactions and check if they make any progress. If they wait for too long and do not progress, then we may suspect there is a deadlock and we can stop the transactions that are running for too long.
Another approach is to analyze the locks and look for cycles in the wait graph. Once we identify a cycle, there is no way to solve the problem other than terminating one of the transactions.
However, deadlocks happen because we use locks. Let’s see another solution that doesn’t use locks at all.
Multiversion Concurrency Control and Snapshots and Deadlock Avoidance
We don’t need to take locks to implement isolation. Instead, we can use snapshot isolation or Multiversion Concurrency Control (MVCC).
MVCC
Optimistic locking, also known as snapshot isolation or Multiversion Concurrency Control (MVCC) is a method for avoiding locks and still providing concurrency. In this method, each row in a table has an associated version number. When a row needs to be modified, it is copied and the copy’s version number is incremented so other transactions can detect the change.
When a transaction begins, it records the current version numbers to establish the state of the rows. During reads, the transaction extracts only those rows that were last modified before the transaction started. Upon modifying data and attempting to commit, the database checks the row versions. If any rows were modified by another transaction in the meantime, the update is rejected, and the transaction is rolled back and must start over.
The idea here is to keep multiple versions of the entities (called snapshots) that can be accessed concurrently. We want the transactions to never wait for other transactions to complete. However, the longer the transaction runs, the higher the chances that the database content will be changed in other transactions. Therefore, long-running transactions have higher chances of observing conflicts. Effectively, more transactions may be rolled back.
This approach is effective when transactions affect different rows, allowing them to commit without issues. It enhances scalability and performance because transactions do not need to acquire locks. However, if transactions frequently modify the same rows, rollbacks will occur often, leading to performance degradation.
Additionally, maintaining row versions increases the database system's complexity. The database must maintain many versions of entities. This increases disk space usage and decreases read and write performance. For instance, MS SQL requires an additional 14 bytes for each regular row (apart from storing the new data).
We also need to remove obsolete versions which may require the stop-the-world process to traverse all the content and rewrite it. This decreases the database performance.
Snapshots
Snapshot isolation levels are another transaction isolation level that databases provide to utilize MVCC. Depending on the database systems, they may be called this way explicitly (like MS SQL’s SNAPSHOT) or may be implemented this way (like Oracle’s SERIALIZABLE or CockroachDB’s REPEATABLE READ). Let’s see how MS SQL implements the MVCC mechanism.
At a glance, MS SQL provides two new isolation levels:
READ COMMITTED SNAPSHOT ISOLATION (RCSI)
SNAPSHOT
However, if you look at the documentation, you can find that only SNAPSHOT is mentioned. This is because you need to reconfigure your database to enable snapshots and this implicitly changes READ COMMITED to RCSI.
Once you enable snapshots, the database uses snapshot scans instead of the regular locking scans. This unblocks the readers and stops locking the entities across all isolation levels! Just by enabling snapshots, you effectively modify all isolation levels at once. Let’s see an example.
If you run these queries with snapshots disabled, you’ll observe that the second transaction needs to wait:
Transaction 1 | Transaction 2 |
SET TRANSACTION ISOLATION LEVEL READ COMMITTED | |
BEGIN TRANSACTION | |
SELECT * FROM People | SET TRANSACTION ISOLATION LEVEL SERIALIZABLE |
SELECT * FROM People | |
This needs to wait | |
COMMIT | |
This can finally return data | |
COMMIT |
However, when you enable snapshots, the second transaction doesn’t wait anymore!
Transaction 1 | Transaction 2 |
SET TRANSACTION ISOLATION LEVEL READ COMMITTED | |
BEGIN TRANSACTION | |
SELECT * FROM People | SET TRANSACTION ISOLATION LEVEL SERIALIZABLE |
SELECT * FROM People | |
This doesn’t wait anymore and returns data immediately | |
COMMIT | COMMIT |
Even though we don’t use snapshot isolation levels explicitly, we still change how the transactions behave.
You can also use the SNAPSHOT isolation level explicitly which is sort of equivalent to SERIALIZABLE. However, it creates a problem called white and black marbles.
White and Black Marbles Problem
Let’s take the following Marbles table:
id | color | row_version |
1 | black | 1 |
2 | white | 1 |
We start with one marble in each color. Let’s now say that we want to run two transactions. First tries to change all black stones into white. Another one tries to do the opposite – it tries to change all whites into blacks. We have the following:
Transaction 1 | Transaction 2 |
UPDATE Marbles SET color = 'white' WHERE color = 'black' | UPDATE Marbles SET color = 'black' WHERE color = 'white' |
Now, if we implement SERIALIZABLE with pessimistic locking, a typical implementation will lock the entire table. After running both of the transactions we end with either two black stones (if first we execute Transaction 1 and then Transaction 2) or two white stones (if we execute Transaction 2 and then Transaction 1).
However, if we use SNAPSHOT, we’ll end up with the following:
id | color | row_version |
1 | white | 2 |
2 | black | 2 |
Since both transactions touch different sets of rows, they can run in parallel. This leads to an unexpected result.
While it may be surprising, this is how Oracle implements its SERIALIZABLE isolation level. You can’t get real serialization and you always get snapshots that are prone to the white and black marbles problem.
Deadlock Avoidance
Snapshots let us avoid deadlocks. Instead of checking if the deadlock happened, we can avoid them entirely if transactions are short enough.
This approach works great when transactions are indeed short-lived. Once we have long-running transactions, the performance of the system degrades rapidly, as these transactions must be retried when they are rolled back. This makes the problem even bigger - not only do we have a slow transaction, but we also need to run it many times to let it succeed.
Consistency Models
The isolation levels define how transactions should be executed from the perspective of a single SQL database. However, they disregard the propagation delay between replicas. Moreover, SQL 92 definitions of isolation levels focus on avoiding read phenomena, but they don’t guarantee that we’ll even read the “correct” data. For instance, READ COMMITTED doesn’t specify that we must read the latest value of the row. We are only guaranteed to read a value that was committed at some point.
Once we consider all these aspects, we end up with a much more complex view of the consistency in distributed systems and databases. Jepsen analyzes the following models.
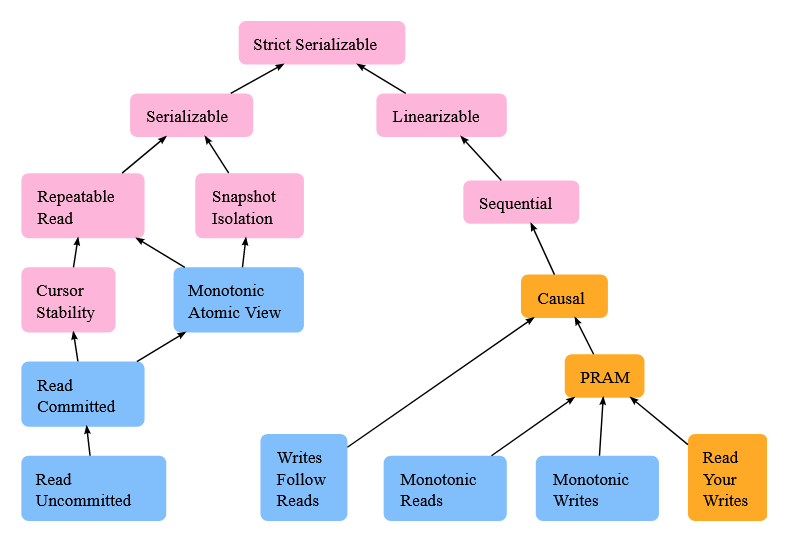
Unfortunately, the terminology is not consistent and other authors define other guarantees, for instance, these by Doug Terry:
Read Your Writes
Monotonic Reads
Bounded Staleness
Consistent Prefix
Eventual Consistency
Strong Consistency
Martin Kleppmann shows the following focusing on the databases:
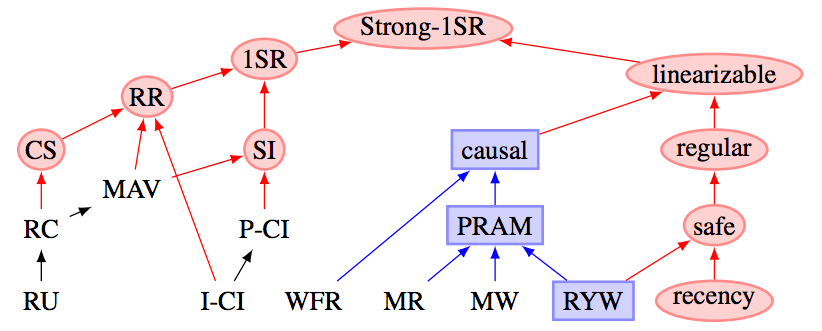
It’s very convenient to consider a couple of read phenomena that we discussed above. Unfortunately, the world is much more complex. The more comprehensive classification includes:
Dirty writes
Dirty reads
Aborted Reads (cascaded aborts)
Intermediate Reads (dirty reads)
Circular Information Flow
Lost Update
Single Anti-dependency Cycles (read skew)
Item Anti-dependency Cycles (write skew on disjoint read)
Observed Transaction Vanishes
Predicate-Many-Preceders
Write Skew variants in the distributed database
The Hermitage project tests isolation levels in various databases. Those are the anomalies that you may expect when using various databases:
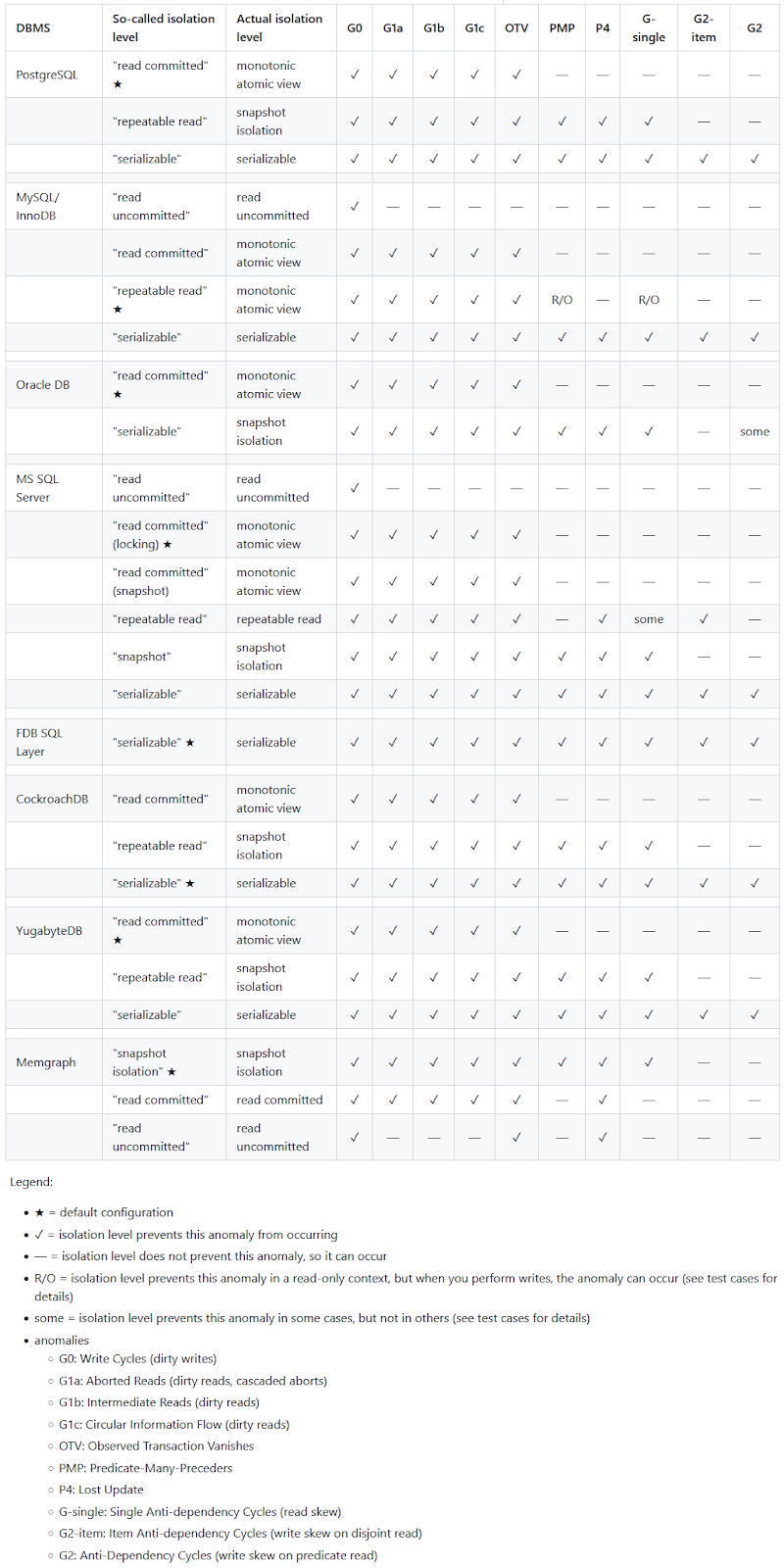
A couple of things worth noting from the image above:
Databases use different default isolation levels.
SERIALIZABLE is very rarely used as a default.
Levels with the same name differ between databases.
There are many more anomalies than only the classic read phenomena.
Add bugs on top of that, and we end up with a pretty unreliable landscape.
Let’s see some of the properties that we would like to preserve in distributed systems and databases.
Eventual Consistency
This is the weakest form of guarantee in which we can only be sure that we read a value that was written in the past. In other words:
We may not read the latest data
If we read twice, we may get the “newer” and “older” values in this order
Reads may not be repeatable
We may not see some value at all
We don’t know when we will get the latest value
Monotonic Reads
This guarantees that when reading the same object many times, we’ll always see the values in non-decreasing write times. In other words, once you read an object’s value written at T, all the subsequent reads will return either the same value or some value that was written after T.
This property focuses on one object only.
Consistent Prefix
This guarantees that we observe an ordered sequence of database writes. This is very similar to Monotonic Reads but applies to all the writes (not a single object only). Once we read an object and get a value written at T, all subsequent reads for all objects will return values that were written at T or later.
Bounded Staleness
This property guarantees that we read values that are not “too old”. In practice, we can measure the “staleness” of the object’s value with a period T. Any read that we perform will return a value that is no older than T.
Read Your Writes
This property guarantees that if we first write a value and then try reading it, then we’ll get the value that we wrote or some newer value. In other words, once we write something at time T, we’ll never read a value that was written before T. This should include our writes that are not completed (committed) yet.
Strong Consistency
This property guarantees that we always read the latest completed write. This is what we would expect from a SERIALIZABLE isolation level (which is not always the case).
Practical Considerations
Based on the discussion above, we can learn the following.
Use Many Levels
We should use many isolation levels depending on our needs. Not every reader needs to see the latest data, and sometimes it’s acceptable to read older values for many hours. Depending on what part of the system we implement, we should always consider with what we need and which guarantees are required.
Less strict isolation levels can greatly improve performance. They lower the requirements of the database system and directly affect how we implement durability, replication, and transaction processing. The fewer requirements we have, the easier it is to implement the system and the faster the system is.
As an example, read this whitepaper explaining how to implement a baseball-keeping score system. Depending on the part of the system, we may require the following properties:
Participant | Properties |
Official scorekeeper | Read My Writes |
Umpire | Strong Consistency |
Radio reporter | Consistent Prefix & Monotonic Reads |
Sportswriter | Bounded Staleness |
Statistician | Strong Consistency, Read My Writes |
Stat watcher | Eventual Consistency |
Using various isolation levels may lead to different system characteristics:
Property | Consistency | Performance | Availability |
Strong Consistency | Excellent | Poor | Poor |
Eventual Consistency | Poor | Excellent | Excellent |
Consistent Prefix | Okay | Good | Excellent |
Bounded Staleness | Good | Okay | Poor |
Monotonic Reads | Okay | Good | Good |
Read My Writes | Okay | Okay | Okay |
Isolation Levels Are Not Mandatory
Databases do not need to implement all isolation levels or implement them in the same way. Many times, databases skip some of the isolation levels to not bother with less popular ones. Similarly, sometimes they implement various levels using similar approaches that provide the same guarantees.
Defaults Matter
We rarely change the default transaction isolation level. When using many incompatible databases, we may face different isolation levels and get different guarantees. For instance, the default isolation level in MySQL is REPEATABLE READ whereas PostgreSQL uses READ COMMITTED. When moving from MySQL to PostgreSQL, your application may stop working correctly.
Database Hints
We can control locking with database hints for each single query we execute. This helps the database engine to optimize for use cases like delayed updates or long-running transactions. Not all databases support that, though.
Avoiding Transactions
The best way to improve performance is to avoid locks and minimize the guarantees that we require. Avoiding transactions and moving to sagas can be helpful.
Summary
Speed and performance are important parts of every database and distributed system. Locks can significantly degrade performance but are often crucial for maintaining ACID and guaranteeing data correctness. Understanding how things work behind the scenes helps us achieve higher performance and great database reliability.







