







A connection pooler is a software component that manages database connections. This can help in multiple ways to improve resource utilization, help with load balancing or failover, and can greatly reduce transaction times. In this blog post, we’re going to see what a connection pooler is and how to configure it.
What Is a Connection Pooler and Why It’s Useful
Opening a connection to the database takes many steps. We need to connect to the server and perform the initial handshake, agree on the encryption and connection settings, and then keep the new connection resource across all the layers (network driver, OS layer, database layer, etc.). Each connection consumes memory which size depends on the database engine. For PostgreSQL, this can be even 1.3MB of memory for one connection. Opening a connection also takes time as we need to negotiate the settings of the new connection.
If we keep opening a new connection for each SQL query, we may cause multiple issues for the database server:
Opening connections takes time and resources, so our transactions are slower
We may exceed the limit of the active connections (which by default can be set to something like a hundred connections)
Database may consume more memory which may negatively affect cache hit ratio and free memory available for queries
Instead of opening a new connection for each SQL query, we can pool the connections. We can configure the connection pooler that keeps the amount of connections and reuses them for all the clients. This way our application connects to the pooler instead of the database directly, and then the pooler connects to the database. This brings multiple advantages:
The connection pooler keeps the connections open for much longer which reduces the overhead of opening and closing the connections on the database end and reduces latency
We can get load balancing between the connections or even between databases which increases performance
The pooler can maintain a stable number of connections, so we avoid the issue of too many active connections which reduces the resource usage
The pooler can redirect the connections between the primary and the standby servers to provide a failover which increases stability and scalability
The pooler can store the password to the database in a central place which increases the security
The pooler can cache the results to improve the query performance
The connection pooler also has some disadvantages:
It’s yet another component in our system which may become a point of failure
Network latency may increase slightly due to another network hop between the application and the database
An inefficient connection pooler may become a bottleneck
We need to tune and maintain the connection pooler which increases the maintenance burden
Different Types of Connection Pooling
There are many ways to implement connection pooling. In this section, we take a look at various implementation details.
External or Internal Connection Pooler
In a typical case, we connect from our application to the database. We can now put a connection pooler in one of two places: in the application itself or somewhere between the application and the database.
Putting the connection pool in the application (application-side connection pooler) can be very easy as many ORMs or database drivers support that out of the box. For instance, JDBC supports that with c3p0 and ODBC supports that out of the box. This brings many benefits. We don’t need to install and maintain any additional components as the pooler lives inside the application. We only need to deploy the new version of the application and we get the pooling ready. This also reduces the network latency, as we don’t have any additional network hops (everything lives inside our application).
Unfortunately, the application-side connection pooler has some drawbacks. The biggest one is that it’s configured for one application only. If we have many applications (especially in a distributed environment), then we need to configure the pooler in many places. Not to mention that we may still hit the connection count limit on the server side as the poolers don’t know about each other. Having many connection poolers also causes higher resource usage and is typically less performant.
We can also use an external connection pooler that sits somewhere between the application and the database. This can work with any number of applications and lets us precisely control the connection limit. A centralized connection pooler can also control resources better and let us achieve failover or load distribution.
External connection pooler also has some drawbacks. First and foremost, it’s yet another component that we need to install, configure, tune, and maintain over time. We also need to reconfigure every application to use the connection pooler (which should be as simple as changing some connection strings and redeploying the application). The external pooler also adds some network latency as it is yet another network component between the application and the database.
The external connection pooler can also become a point of failure. If the pooler is down for whatever reason, applications cannot connect to the database anymore. If the pooler is slow or inefficient, then it affects all the applications using it. Therefore, the pooler must be of a high quality to not deteriorate the overall performance.
Types of Pooling
Each pooler needs to decide on how to assign connections to the clients. There are generally three approaches.
The first one is session pooling. In this approach, the connection is assigned to the client for the duration of the session (so until the client disconnects or a timeout is reached). This is the easiest approach, however, this effectively limits the number of clients as typically each client consumes one connection.
The next solution is transaction pooling. In this approach, the pooler assigns the connection for each transaction and only for the transaction duration. If a client wants to run another transaction, they need to get another connection (and may need to wait for some other connection to be available). This allows the pooler to handle more clients and is the recommended approach.
The last approach is to assign the connection for each SQL statement independently. In theory, this brings the highest flexibility and connection utilization. However, this causes one transaction to span across many connections. Since many transaction settings are tied to the connection, this may become a technical limitation.
Connection Pooling Solutions
Depending on the database type you use, there may be some built-in solutions, or you may need to configure them manually. Let’s see some examples.
Built-in Solutions
Depending on your infrastructure provider, you may be able to use built-in or nearly-built-in solutions:
Neon PostgreSQL database has a built-in PgBouncer
DigitalOcean’s PostgreSQL includes PgBouncer
Azure database can be used with ProxySql
Azure database can be used with Heimdall Database Proxy
ADO.NET supports a built-in connection pool
Oracle supports Universal Connection pool for JDBC
Oracle Autonomous Database supports Database Resident Connection Pool
External Solutions
There are many external solutions that you can use:
Case Study: Configuring PgBouncer
In this example, we’re going to examine PgBouncer.
We start by installing it as in the documentation.
We then need to configure it. The most important settings are:
pool_mode - how to handle connections; we can use transaction
max_client_conn - this configures how many clients can connect to the connection pooler
default_pool_size - configures how many server connections are allowed for each user + database
min_pool_size - how many standby connections to keep
After configuring the pooler, we can verify its performance with pgbench:
pgbench -c 10 -p -j 2 -t 1000 database_name
PgBouncer can easily increase the number of transactions per second by 60%, as shown in benchmarks:
https://stackoverflow.blog/2020/10/14/improve-database-performance-with-connection-pooling/
https://www.thediscoblog.com/supercharging-postgres-with-pgbouncer/
How Metis Helps
Metis can track the number of connections:
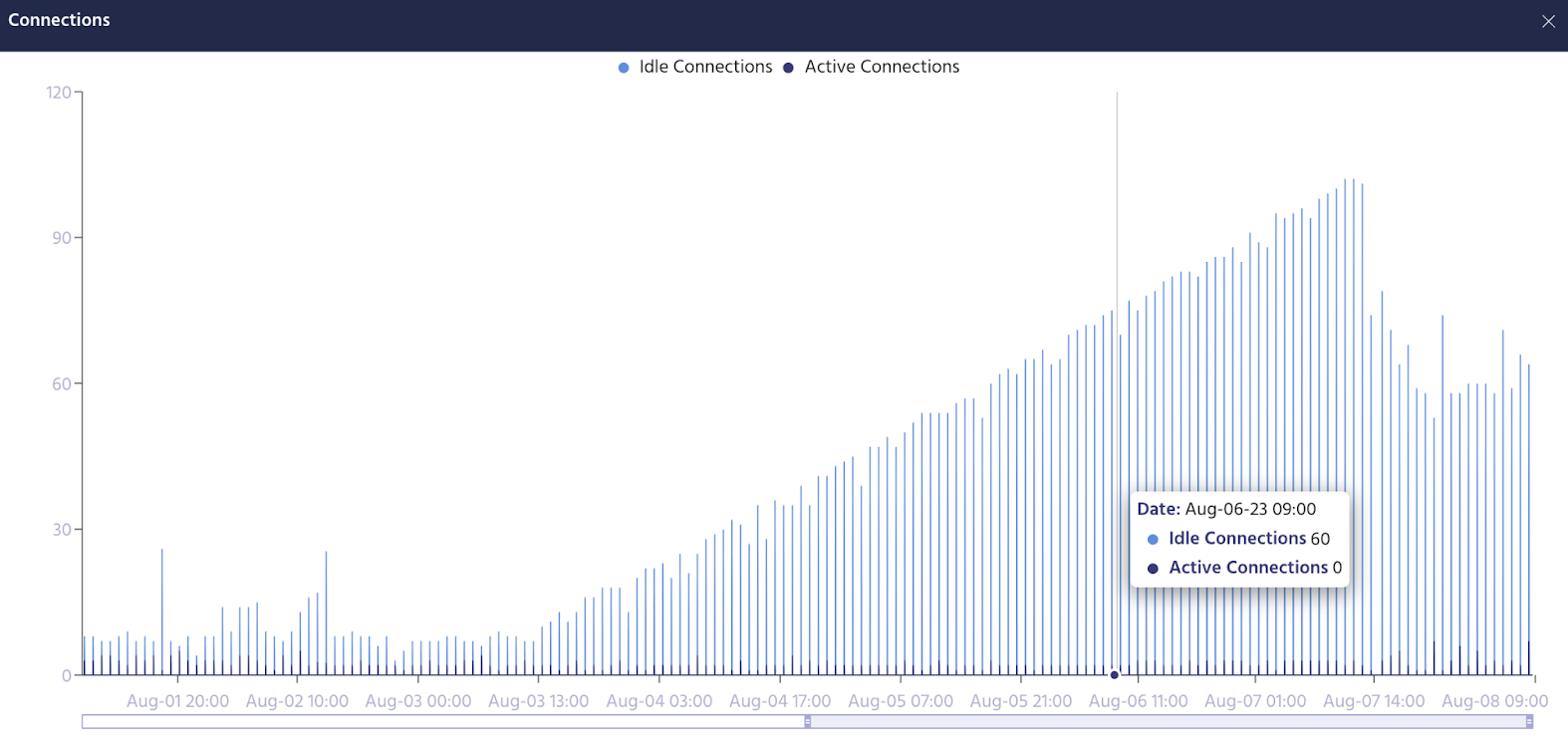
This way you can easily detect issues, just like it happened to us.







