







Disk activity is much slower than reading data from RAM. With today’s performance characteristics, reading from DRAM takes around 100 nanoseconds whereas reading from the physical drive is between 10 microseconds (for SSD) up to 10 milliseconds (for HHD). This is up to 100,000 times slower than accessing the random access memory. Reading from the L1 cache is even faster and can take 3 CPU cycles which is less than 1 nanosecond. Therefore, every read from a physical drive is a tremendous performance hit and should be avoided. In this blog post, we are going to see how to debug scenarios where we can’t utilize cached data and need to read from the physical drive. We’re going to see why it’s important, what to look for, and what tools and extensions to use.
How Databases Read Data
Databases are well aware of performance issues when reading data directly from the hard drive. Therefore, they incorporate many sophisticated techniques to boost performance and cache data where possible. Let’s see how the database can access the data and what happens next.
Various Ways of Reading Data
The most basic approach is when the database needs to read the table that has no clustered index configured. Such a table is sometimes called the heap. The engine needs to simply scan each row one by one, filter them accordingly, and then process them further.
The data is stored in so-called pages. The database engine chunks the data into smaller pieces and then stores these pieces on the drive. Each piece is called a page and commonly is 8kB long (that is configurable, though). Unfortunately, some space is wasted as the databases typically don’t allow for a row to span multiple pages. This phenomenon is called “fragmentation” and leads to some space waste. When scanning the whole table, the database engine must read more than the actual size of the data which makes the whole process even slower.
Things get complicated even more when we consider data modifications. When we remove a row, the database engine must remove it from the page which is rarely done. More often, the database just marks the row as removed (“dead”), and then ignores it when scanning the table. However, the database still needs to read the dead rows which may decrease the performance even more when we have many dead tuples.
This means that over time our database will get slower. To aid that, we need to defragment the tables (sometimes called “vacuuming”). This process makes the database read all data and write it on the side in a more organized way to remove the dead tuples and recover some wasted space.
Because of all these internal details, the database engine has many ways to speed things up. The first approach is to scan the table in parallel with multiple writers. This makes things faster if we can perform multiple reads at once, which is often possible when we keep our drives in RAID clusters. However, the true game changer is indexing.
A clustered index is a structure that holds the data in a B-tree (which is a generalized binary tree). All the rows are ordered based on some properties like the row number, and therefore we can search for the rows much faster. Most importantly, we don’t need to read all the data to find rows based on their identifiers. This way we can avoid expensive reads and “jump” to the required entities easily. It’s important to understand that when we configure a clustered index on a table, the index becomes the table. If it’s possible, all the data is held in the index nodes. This somewhat decreases the read performance (as we need to read the big rows in their entirety) but still lets us utilize the indexing and binary search. If we don’t want to store the whole data in the index nodes, we can build additional indexes that would include only some of the columns and the pointers to the actual rows, and then the database would first read from the auxiliary index, and then go to the main table to get the rows’ contents.
There are many more techniques to improve performance (like bitmap scans, column stores, and other types of indexes), however, all of them focus on this one simple thing - read as little as possible.
What Happens After Reads
Once the data is read from the drive, the database engine may want to keep it in memory to speed up the following operations. Therefore, each page may be stored in the cache. Depending on the database type, there may be many levels of caching and different caching strategies. We can intuitively think of these as some part of RAM that is used to keep what has been read from the drive even after we processed the data entirely.
Database cache is just one level of caching. Another level is the operating system level cache, and yet another is the CPU cache. Even if we can’t find the data in the database cache, it may still be cached by the operating system (so the filesystem doesn’t need to read from the drive), or in the CPU cache. The actual caching works like this when the database wants to read a memory page:
First, the database checks its own cache. If the data is there, then the database wants to read it
To read from the database cache, the database wants to read from some actual DRAM memory address. Before going to DRAM, the CPU cache is consulted (first L1, then L2, and L3). If the data is not there, then the CPU gets the data from the DRAM, fills CPU caches, and proceeds further.
If the data is not in the database cache, then the database issues a read from some memory page (which in turn is some part of an actual file on the drive). At this point, the file system checks if the file portion is already in the file system cache (which in turn is stored in the DRAM memory, so CPU caches are consulted again). If the data is there, then it’s returned from the DRAM memory. Otherwise, the file system goes to the drive.
The drive has its own cache again. It checks if the data is there and returns it if possible. Otherwise, the actual physical drive is read and the data is stored in the drive cache, file system cache, database cache, and CPU cache.
If any of these caches is full, we need to evict some old entries. There are many strategies for doing so (most notably the Least-Recently-Used (LRU) that removes the entry that wasn’t used for the longest time). This means that putting some “fresh” data causes some “old” data to be removed from the cache
As we can see, there are so many caches along the way. While we rarely focus on these technical details, there are a couple of points that we need to understand:
To make things faster, we need to keep our caches utilized as much as possible
Reading some “new” data can affect performance in a very distant place. For instance, the file system reading data for the operating system updates may evict some entries from the file system cache that would serve the database. Therefore, operating system updates may impact the performance of the database
The cache size that we configure for the database is not “the only” cache that we use
It is fair to say that it’s always better to not keep unused data in memory as it may affect some other operations. Where possible, remove everything that you don’t need!
What Goes Wrong When Caches Are Underutilized
Many things go wrong when the caches are used inefficiently.
First and foremost, the latency increases. That is the natural consequence of the database reading data from the slower data source (hard drive rather than CPU caches or database caches). This in turn increases the duration of the user-facing operations and negatively affects the performance of everything.
Next, low cache utilization leads to a higher load on other parts of the ecosystem. The file system needs to read more data, the drives need to read more, and other processes are slowed down. Everything gets slower if we can’t use the caches.
Next, we increase the resource usage and lower the energy efficiency. Since our devices consume energy mostly when transistors change their state and the physical devices do some work, underutilizing caches leads to more energy consumption. Similarly, we need to read more data from the drives which overloads the system bus or network connections, and that in turn causes other resources to be used more.
Higher resource usage leads to increased failures. Physical devices break when they are used more, so using them more frequently leads to more hardware failures and problems along the way. This leads to crashes, systems become unresponsive, and we may face downtime or data loss.
In short, a low cache hit ratio negatively impacts everything. Therefore, we should aim for the highest possible cache utilization.
The Whole Point of Caching And How to Make Caches Great
Cache utilization greatly depends on how you interact with your data. We typically assume that the database serves the OLTP workload in which we assume that a particular row may be used multiple times, preferably by multiple transactions. In that case, it’s beneficial to cache that row to avoid going to disk (which we know is much slower). Once the row is cached, the transactions can read it from the cache which sits in the RAM and makes it much faster.
However, if your workload is not OLTP, then the assumption doesn’t hold. One particular row may be used just once and never reused again. In that case, putting it in the cache doesn’t bring any value as we don’t get any benefits from that. It’s actually even worse, as we still need to manage the cache and therefore we may get reduced performance.
The first thing to understand when dealing with caches is analyzing what the workload is. If the system servers the OLTP workload, then we may expect that increasing the cache size will improve the performance. We can simply validate that by making the cache bigger and verifying if our cache hit ratio increases. There is much more to that due to inefficient queries, fragmentation, indexes, operating systems, etc., but in essence, it all goes down to increasing the cache and checking if that helps. This may also go the opposite way - you can decrease the cache size and check if your metrics decreased just a bit which may suggest that your cache is too big and doesn’t bring more value anymore.
However, if the system servers to warehousing or reporting scenario, then we may actually want to make caches small (like kilobytes small) to avoid the penalty of maintaining them since we don’t get any benefits from them. To understand if that’s the case, we need to verify what queries we run, what data flows into the system, and what is cached over time. We can also apply some standard strategies that help the database “in general” and can directly affect the cache performance. Read on to understand them.
How to Improve the Cache Hit Ratio
There are many aspects of the database system that we need to optimize to improve the cache hit ratio. Let’s walk through them.
Slow Queries
As stated before, we should process as little data as possible. We should always aim to optimize queries where applicable. This includes things like:
Using indexes where possible to minimize the data reads
Use filtering efficiently to process fewer rows and filter them as early as possible
Avoid temporary data that needs to be stored on the side and would consume the caches
Remove unneeded columns or joins
Denormalize data where possible to operate on identifiers instead of entire rows
Avoid stringly-typed queries and prefer direct ones
Use materialized views where possible
Split queries into smaller ones to avoid joins
Avoid locks
Make sure statistics are up to date to not run into inefficient query plans
Remove dead rows
There are many more aspects that we could focus on. They all go down to this simple rule - read as little as possible and avoid polluting caches.
Indexes
To improve the cache hit ratio, we can simply read less data. To do that, we can use indexes where possible to make the database only access the needed entities.
Analyze all your queries and configure indexes where applicable. This can be done automatically thanks to tools like Metis that can analyze your queries and immediately detect slow table scans.
Static Configuration
One of the aspects that we can tune directly is cache configuration. Depending on the database engine we use, there are many tunable parameters. For instance, PostgreSQL uses shared_buffers, effective_cache_size, and work_mem among others.
You should always tune these parameters for your specific workload and hosting infrastructure. You can also check our guide for PostgreSQL configuration to make sure you have your database running blazingly fast.
Fragmentation
Table fragmentation negatively impacts the performance. Since we have dead rows, the database engine wastes time on reading those and then ignoring them. There are many reasons for fragmentation.
The first reason is that we constantly modify the data. Using column types like varchar may cause fragmentation as the rows change their sizes. Imagine that you update a row that is stored somewhere in the middle of the page, and the update causes the row to become bigger (because you stored a bigger string in one of the columns). Such a row can’t fit into the page anymore and must be moved somewhere else. Therefore, the database needs to move the row somewhere else which in turn causes the database engine to use one more memory page when reading the data.
Another scenario is when you want to insert a new row between two other rows. This can happen when you store the data in an ordered fashion (like in a clustered index) and you add a row somewhere in the middle instead of at the end. To keep the order on the drive, the database engine needs to put the row somewhere else and use pointers to keep the order. In less frequent cases, this can lead to the clustered indexes not being sorted anymore which requires the database to sort the rows again after reading them.
To avoid these issues, we need to remove dead tuples periodically to decrease fragmentation. To do that, we need to vacuum the tables which takes time and must be done carefully to not impact ongoing transactions.
Unused Indexes
When we have auxiliary indexes configured on the table, the database engine needs to keep them in sync with the table content. This means that each modification query must update the data in multiple places - in the table itself, and all the indexes. To update the indexes, the database must bring them to memory which in turn causes lower cache utilization.
To avoid this issue, remove all the indexes that you don’t need. Simply analyze their usage over time and drop them as soon as possible.
Operating System
The operating system may affect the memory usage as well. For instance, Linux allows for overcommitting and has its infamous Out-Of-Memory (OOM) Killer that kills the processes that use too much memory. Even though your process thinks it successfully allocated the memory, the operating system may decide to kill it later on because some other process wanted to allocate some memory and the operating system decided it’s not enough memory for everyone.
To avoid the issue, tune your OOM Killer to not kill your database process and kill something else instead. You may even consider disabling the memory overcommitting to avoid the issue entirely.
More Memory
One of the most obvious solutions to a low cache hit ratio is to make bigger caches. Simply add memory to your machine and configure caches to use this additional memory.
How to Use pg_buffercache
pg_buffercache is a PostgreSQL extension that lets you examine what’s happening in the shared buffer cache of your database. It provides functions that can show you the cache pages, statistics, and a summary of what’s going on.
To use the extension, simply install it with
create extension pg_buffercache;
The extension provides a view pg_buffercache that lists the following data:
bufferid - the block ID in the server buffer cache
relfilenode - the node number of the relation
reltablespace - object identifier type (OID) that the tablespace uses
reldatabase - OID of the database
relforknumber - fork number within the relation
relblocknumber - page number within the relation
isdirty - flag indicating whether a given page is dirty
usagecount - access count statistic
pinning_backends_integer - how many backends pin this buffer
Since the extension operates on pages, we need to divide our cache memory size by 8kB. So if we have 256MB of shared_buffers with the default page size of 8kB, we’ll have 32,768 buffer blocks. Therefore, the view pg_buffercache will have the same number of rows (one row for each block).
We can use the extension to find the tables that use the cache. For instance, this query shows how many buffers each table consumes:
SELECT c.relname AS relation_name, count(*) AS buffers
FROM pg_buffercache b
INNER JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid) AND b.reldatabase IN (0, (SELECT oid FROM pg_database WHERE datname = current_database()))
GROUP BY c.relname
ORDER BY 2 DESC
LIMIT 10;
| # | relation_name | buffers |
|---|---|---|
| 1 | name_basics | 445 |
| 2 | name_basics_pkey | 50 |
| 3 | pk_title_principals | 197 |
| 4 | title_basics | 6326 |
| 5 | title_basics_pkey | 2299 |
| 6 | title_crew | 940 |
| 7 | title_crew_pkey | 99 |
| 8 | title_principals | 949 |
| 9 | title_ratings | 2149 |
| 10 | title_ratings_indexed | 2272 |
This query shows how much of the buffer is used by each table and how much of that table is actually buffered:
SELECT
c.relname,
pg_size_pretty(count(*) * 8192) as buffered,
round(100.0 * count(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent,
round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation
FROM pg_class c
INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database())
WHERE pg_relation_size(c.oid) > 0
GROUP BY c.oid, c.relname
ORDER BY 3 DESC
LIMIT 10;
| # | relname | buffered | buffers_percent | percent_of_relation |
|---|---|---|---|---|
| 1 | title_basics | 51 | MB | 39.6 |
| 2 | title_basics_pkey | 47 | MB | 36.4 |
| 3 | title_ratings | 26 | MB | 20.1 |
| 4 | title_principals | 2504 | kB | 1.9 |
| 5 | name_basics | 256 | kB | 0.2 |
| 6 | pk_title_principals | 72 | kB | 0.1 |
| 7 | title_principals_nconst_idx | 88 | kB | 0.1 |
| 8 | pg_operator | 88 | kB | 0.1 |
| 9 | pg_statistic | 72 | kB | 0.1 |
| 10 | pg_index | 48 | kB | 0.0 |
You can use the extension to track which tables consume your buffers and verify if that’s expected.
Once you see what’s in your caches, and you understand if your workload is OLTP (and the caches should help in theory), then you can tune the cache size. If you observe that caches change too often (for instance you see different tables in the cache every minute), then it’s probably worth increasing the cache size and the hit ratio should increase (and so the overall performance). At the same time, if you see that most of the cache remains stable, then you may consider lowering your cache size which shouldn’t affect the hit ratio much and the performance shouldn’t degrade. After each cache size modification, you can analyze the cache content with pg_buffercache and verify your assumptions.
So the actual process is:
Start with something like 1GB of shared buffer memory for your database
Check hits and misses with pg_buffercache
Add some more shared buffer memory (like an additional 10% or 1GB)
Check hits and misses again. The hits should increase at this point
Continue adding the memory until you see that your hit rates do not increase anymore
You can use the same reasoning to lower the cache memory size without breaking the system's performance.
How Metis Helps
Metis can help with low cache hit ratio by providing actionable insights into query optimization. For instance, Metis shows how to make the queries faster:
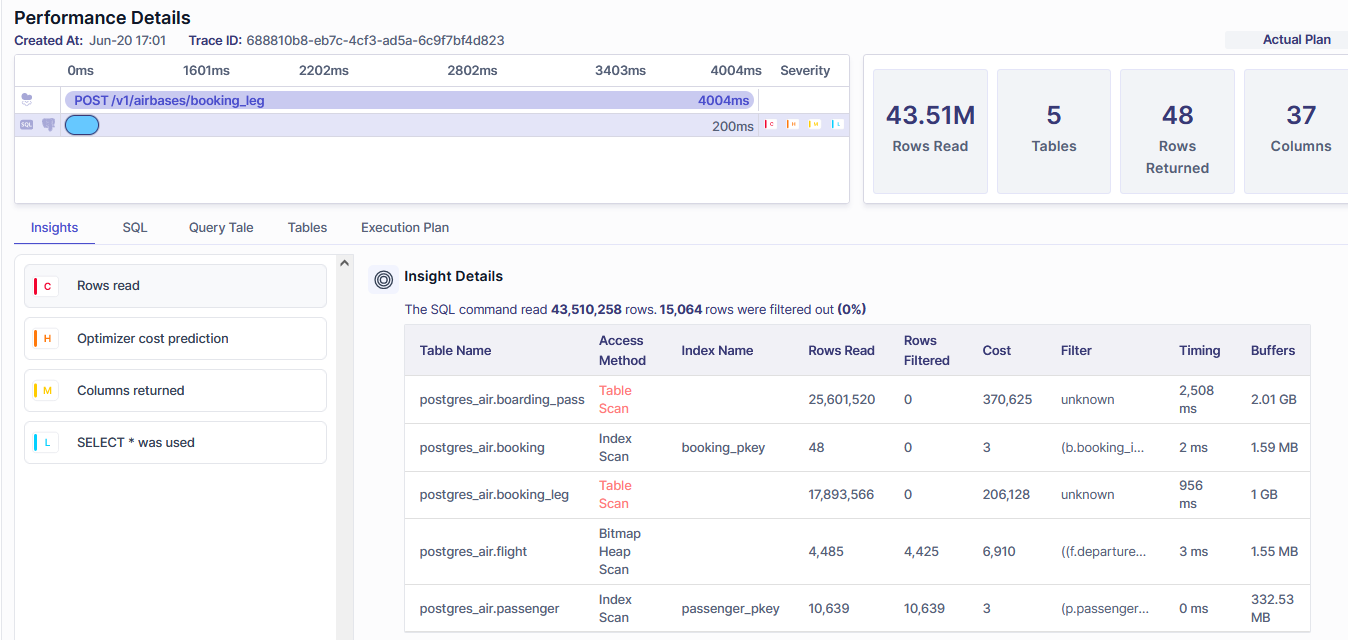
Metis analyzes your tables and can provide insights into how to make the schemas better:
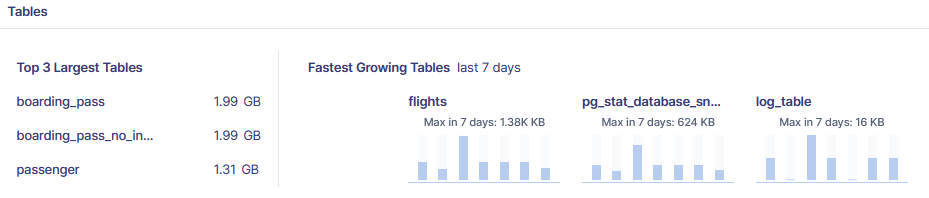
Metis can identify unused indexes:
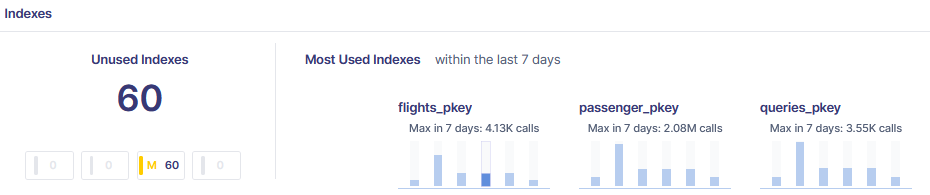
Finally, Metis tracks your live queries and provides statistics about the performance:
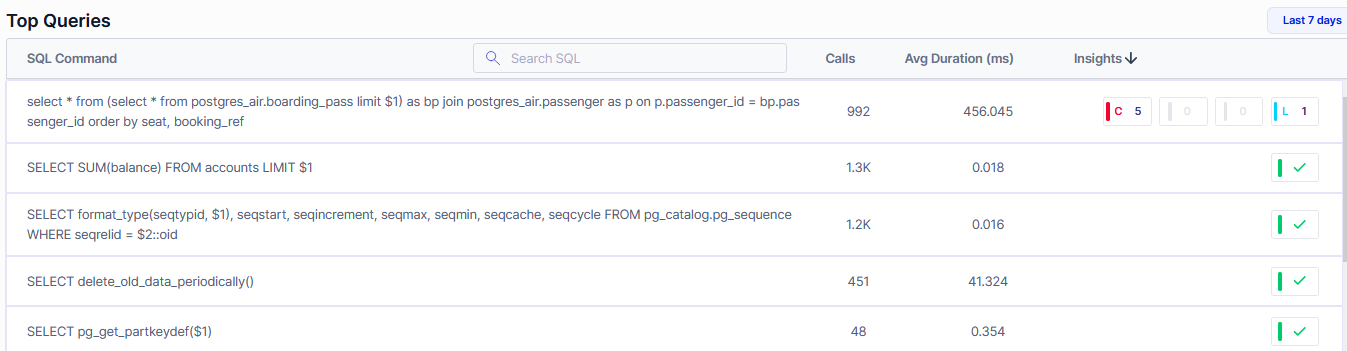
Summary
Optimizing a low cache hit ratio is crucial for keeping the database in good shape. Caches greatly affect the performance of the whole system and many moving parts can affect the cache utilization. pg_buffercache extension can help with the analysis of memory buffers and show you what to focus on. Metis can automate the optimization process for you and show you actionable insights to improve performance







