







The complexity of our applications increased enormously in recent years. We face hundreds of clusters and databases, often heterogeneous and incompatible with each other. We deploy multi-tenant applications for which we implement well-crafted solutions for tenants separately. We deploy things many times a day, automate as much as possible, and rely on monitoring and metrics to alert us about the issues. And yet, databases still fail and we need to maintain them 24/7.
Imagine a world where you don’t have to worry about your database, no bugs are deployed to production, all the performance checks happen early during the development phase, you don’t need DBAs nor the maintenance team, and still, everything works great. No matter how fantastic that sounds, you can get it today. Read on to learn how.
When running multi-tenant applications spanning hundreds of clusters and databases, it’s not uncommon to build extensive maintenance pipelines, monitoring, and on-call rotations to achieve database reliability. Many things can break, starting with bugs, inefficient queries written by developers, or inefficient configuration and indexing. Do you worry about your databases? You’re doing it wrong. Read on to see how to stop worrying and still have continuous database reliability.
The World Today
In recent years, the sophistication of our applications has undergone a dramatic surge, presenting us with a myriad of challenges. 20 years ago we had one application with one database. Today we have hundreds of clusters and databases. Yet, just like we were expected to deploy early and often 20 years ago, we still want to move fast today. This poses many challenges:
We don’t know what’s already deployed and which things are still going through pipelines
It’s hard for us to debug issues when they cover multiple pipelines, subsystems, and databases
We need to involve many teams to maintain the solutions: developers, DevOps engineers, DBAs, and others
Teams need to communicate with each other and can’t self-serve their issues
The complexity will not decrease. It’s going to be harder and harder over the years. Therefore, we invest heavily in tools that are supposed to help us but mislead us even more instead.
First, we test our solutions with various tests from the testing pyramid. However, these tests focus on correctness only, disregarding performance or other non-functional requirements. Our tests can capture if we read and write data correctly, but they won’t find that we used N+1 queries or didn’t use an index to read the data. Performance issues will go unnoticed.
Second, we don’t test how we introduce changes to the database. We just run schema migrations and we assume they’ll run fast and well. However, they may need to rewrite tables which will take our databases offline for hours. We don’t have solutions to identify these things in advance because we use small databases in our local environments.
Third, we use load tests to assess the performance, which is slow, expensive and happens far too late in the pipeline. If we identify issues during load tests, we need to start the development process again from the very beginning. We need to come back to the whiteboard even though we wrote the code, reviewed it, committed, and even deployed it through pipelines. This is way too expensive. Not to mention, that we need to build and maintain load tests which cost money, and can pose security issues (for instance around GDPR).
Fourth, our monitoring solutions don’t help. They swamp us with raw data and myriads of metrics, but they don’t present the root causes and how to fix things. They simply show all they have and assume that we’ll do the hard work to figure out how to fix the issues.
Recommended reading: All Your Monitoring Solutions Are Wrong, Here's Why
Five and foremost, our teams need to work together and cannot self-serve their issues. Developers lack knowledge of databases, so they need to get help from other teams. Other teams are already swamped with hundreds of databases they need to maintain. Communication is slow, tickets between teams make that even slower, and we need to reshuffle our teams and priorities every week to keep our systems up and running.
It’s no surprise that we constantly worry about our databases. We have no way to prevent the bad code from reaching production, fix issues automatically, or unleash the potential of our teams to improve their velocity and remove MTTR. Or do we? What if I tell you it’s possible to have all of that today?
Imagine a World Where Databases Do Not Break
What you need today is database guardrails. You need to have mechanisms that can:
Reduce MTTR by automating troubleshooting and fixing
Improve velocity by avoiding rollbacks, performing checks early in the pipeline, and identifying issues before they appear
Promote self-servicing over slow communication
Increase the number of deployments and shorten the process of implementation and delivery
Provide continuous database reliability and alert you only when things require business decisions
Metis gives you all of that. Let’s see that in detail.
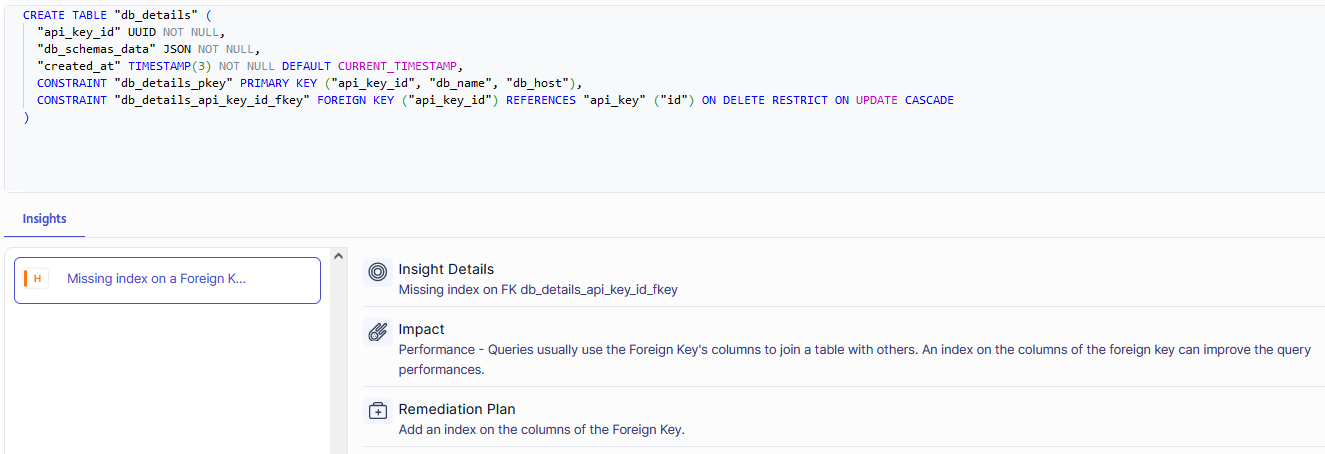
Metis automates troubleshooting and fixing which directly reduces your MTTR. Metis analyzes your queries and looks for anomalies to give you insights into how things work. Metis can tell you if you don’t use indexes, filter data inefficiently, or your queries use non-optimal execution plans. All of that is in real-time for the queries that come to your database.

Metis checks your queries, schema migrations, and database interactions during your development time. All the issues are identified even before developers commit their code to the repository. Metis integrates with your CI/CD pipelines and can stop your changes from breaking production. Your testing pyramid is enhanced to cover execution plans, indexes, dangerous schema migrations, or inefficient querying techniques. This lets you avoid rollbacks from production, faulty deployments, or finding issues during load tests at the very end of your pipeline. Metis directly increases the velocity and reliability of your development process.


Metis lets developers own their databases. Developers get database-oriented metrics that they can use to assess the performance and the state of their databases. They don’t need to wait for input from other teams (be it DBAs or operations), and they can self-service their issues. Metis automates troubleshooting which gives you continuous database reliability. Your teams don’t slow down waiting for others. Your teams can work independently, own more, and self-service everything around databases.

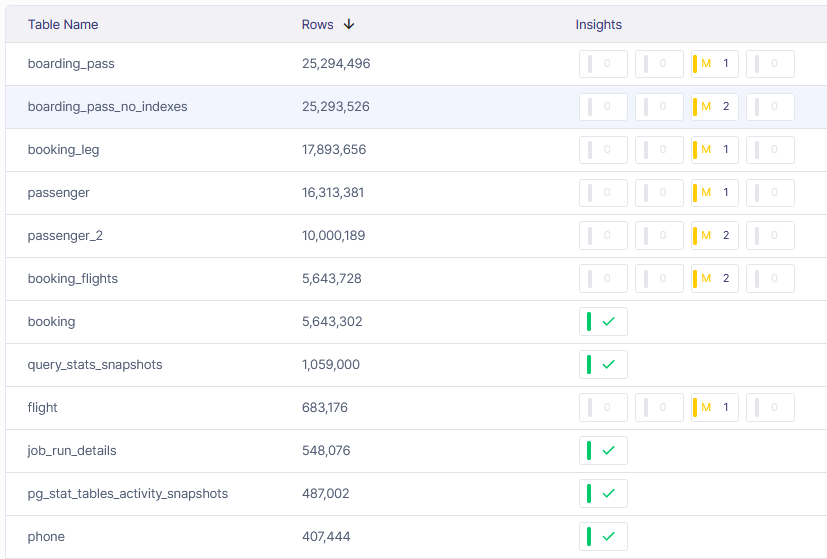
Metis helps you improve your application architecture. Metis can assess your schemas, configurations, extensions, indexes, partitioning, and everything else that directly impacts your designs. With Metis, you can validate your designs before you commit your code to the repository. This lets you shorten your development cycles, deploy more, and move faster. Metis Lets you deliver more in a shorter time.
Metis integrates with your ecosystem. Metis can fix your technical issues automatically and can alert you for cases that require your business decisions. You don’t need to tune the alerts or spend time reviewing metrics. Metis lets you do your business by taking care of your technology.

Database guardrails provided by Metis are a way to give you continuous database reliability. You can focus on bringing more value to your customers instead of thinking about your databases. Let Metis do the worrying for you!
Summary
Navigating through any clusters, heterogeneous, and multi-tenant applications can be challenging. However, having the right tools can help us automate troubleshooting, increase our velocity, reduce MTTR, and let teams self-service their issues. Metis helps you achieve all of that thanks to features that prevent the bad code from reaching production, automate troubleshooting, and provide observability for all you do. Use Metis and achieve continuous database reliability.







