







Memory usage is one of the most important aspects of the database system. Having not enough memory directly affects every performance metric and negatively impacts the performance. This in turn affects our users and the business. In this blog post, we are going to understand how databases (and PostgreSQL specifically) manage memory and how to troubleshoot low free-memory scenarios.
How Databases Read Data
To understand how to deal with memory, we need to understand how things work. Let’s see some basic databases and operating systems mechanisms.
Memory Pages
Databases need to organize the data in a way that improves performance and makes reads and writes easier to handle. To achieve the best performance, the workload must be predictable and divided into manageable chunks. Databases achieve that with pages.
A page in the context of databases is a fixed-length block of data that represents the smallest unit of storage that the database system deals with. Pages let the database organize the data on the disk efficiently, which in turn improves performance and makes the workloads predictable.
The page size parameter decides how big the page is. Typically, it is set to 8192 bytes (8kB) and some databases allow the users to configure it, for instance, block_size in PostgreSQL. Pages can be grouped in so-called extents that make page management easier.
The database is effectively stored in pages. Each disk read or write ultimately goes down to reading or writing the whole page which means writing 8 kilobytes of data. Even if we want to read one byte of data (like a single bit column from one row in the table), we need to load the whole page to memory.
Fragmentation
Typically, databases store one table row on one page only. They don’t allow for the row to be stored on multiple pages. This leads to a phenomenon called fragmentation. Each row may have a different length, especially if we use variable-length types like varchar. To utilize the memory efficiently, databases try to store the rows one after another. If we now modify a row that is between two other rows, then the modified row may become larger and can’t be stored on the page anymore. To handle this problem, the database must move the row somewhere else, and the original space will become empty (or will have a pointer to the new place). This space is now wasted and causes fragmentation.
Prefetch and Performance
Reads and writes are much faster when the pages form a continuous memory block. This utilizes the memory prefetching mechanisms in which the Memory Management Unit (MMU) predicts which memory pages will be accessed in the immediate future and loads them earlier. If the prediction is correct, then the overall performance increases as the MMU reads the data earlier. To make the predictions better, the memory must form a continuous block (so the pages must be one after another in the physical memory).
The typical page size is 8 kilobytes. This works well for most situations, however, sometimes we would like to have much bigger pages to reduce the number of read and write operations. The page size is mostly dictated by the operating system and the CPU architecture. Since the operating systems typically use 8kB pages, the database system wants to use the same setting. To reduce the number of I/O operations, we need to make the pages bigger. To do that, we can use the so-called huge pages that can be 2MB, 1GB, or even 16GB long. We need to enable them in the operating system and then in the database. For instance, PostgreSQL uses the huge_page_size parameter for that. By enabling huge pages, the database can get much bigger pages which reduces the number of I/O reads and writes the database must perform. This also makes pages form bigger continuous blocks which improves the prefetching and the overall performance.
However, the operating system may fiddle with the page size dynamically. For instance, Linux supports the Transparent Huge Pages (THP) which automatically promotes and demotes the page sizes. This hides the huge pages from the application and in theory can improve the performance when the application doesn’t use huge pages, as the operating system may merge multiple application pages into one huge page. Unfortunately, when the application uses huge pages explicitly and the operating system represents huge pages as regular pages behind the scenes, performance degrades very quickly. If you enable huge pages in your database, then disable THP in the operating system.
Overcommitting
Operating systems may also cheat about how much memory is allocated for the application. When the application tries to allocate the memory, the operating system always confirms that the memory has been allocated even if there is no available memory. This is called overcommitting.
This approach improves the usability of the system when many applications run. Applications typically allocate bigger buffers than they need to be prepared for bigger input data. Even if the applications don’t use the memory, the operating system would need to allocate the big blocks which would quickly exhaust the resources and fewer applications would be able to run.
To avoid this problem, the operating system pretends that all memory allocations were fulfilled and the memory is available. Only when the application tries to access the data does the operating system throw the exception that there is not enough memory. In that case, the Out-Of-Memory-Killer may kick in and kill one of the processes. It’s all good when the applications don’t want to utilize more memory than the machine has physically. If they want to use it, then the problem begins.
This is often the case with databases. They want to allocate big memory blocks at the start to be prepared for any workload. Unfortunately, the operating system will simply pretend like the memory has been allocated even if it’s not available. Therefore, disable overcommitting in your operating system. In Linux, you can use vm.overcommit_memory.
How PostgreSQL Allocates Memory
Each database allocates memory differently. In this section, we focus on PostgreSQL.
When the PostgreSQL server starts, it allocates many different memory blocks. Let’s see them one by one.
Shared Buffers
The most important lock of memory is called shared buffers. It’s the block of memory that is used to cache the most often used pages (so rows, indexes, and other things in your database). The database uses a couple of metrics to identify the most popular pages, but they mostly come down to counting reads and writes. Interestingly enough, you can even read a page and redirect it to /dev/null to make it cached in shared buffers because PostgreSQL checks the operating system metrics as well.
Shared buffers are allocated at the start and they can’t change size during the execution. Therefore, to change the size, you need to restart the database.
Shared buffers are the most important part of the memory for your database. The default size is set to 128MB and the general recommendation is to set it to 25% of the machine’s RAM. However, this is a very old and inaccurate recommendation, so read on to understand how to tune it, and also see our other article about troubleshooting cache hit ratio to learn more.
Working Memory
Another block of memory is the working memory that is allocated for each execution node in each query. This memory is used to process the output of the node and produce the result. Therefore, the more queries and nodes we have, the more memory we use.
To understand how this works, we need to understand how queries are executed. Whenever we run a query, the database must execute it in stages. First, it extracts the data from the tables and runs joins. Next, the database does filtering and other processing. Finally, the results are sorted. At each stage, the database may need to generate a big chunk of data (like the content of a table) which consumes a lot of memory.
Without going much into detail, each such operation may be a node in the execution plan. Therefore, one query reading from multiple tables may have multiple execution plan nodes. For each such node, the database allocates the working memory. If the result set from the node is bigger than the working memory, it is spilled to disk (which is much slower than holding the data in RAM).
The work_mem setting in PostgreSQL controls how much memory is allocated for each execution node in each query. By default, it is set to 4MB. It is generally recommended to set this parameter to the amount of total RAM divided by the number of connections and then by 4 or 16. This depends on the workload you are running, so read on to understand how to tune it.
Maintenance Working Memory
The next block of memory we are going to consider is the maintenance working memory. This block is used to perform background operations like vacuuming (defragmentation), index creation, or DDL operations (like adding foreign keys).
Each background task gets its own block, so if you have many autovacuum processes running, then each of them will get its own memory. By default, the size of this block is set to 64MB. It’s generally recommended to set it to higher values like 1GB if your server can handle that.
Temporary Buffers
Each session gets another block of memory that is used for session-local buffers. This block is used for creating temporary data like temp tables. The session allocates temporary buffers as needed.
By default, each session is allowed to allocate 8MB of temporary buffers. This memory is not shared with other sessions and is private to a session. If you deal with sessions that allocate many temporary tables, then you may consider tuning this parameter.
Tuning the Memory
Let’s now see how to tune the memory in the PostgreSQL server.
Static Configuration
First and foremost, you need to tune the configuration.
shared_buffers
The typical recommendation for the shared_buffers parameter is to set it to 25% of the RAM. That’s a good starting point, but it doesn’t tell the story.
Memory utilization greatly depends on how you interact with your data. If you run an OLTP system, then we can assume that many transactions will touch the same rows in a short period. In that case, it’s beneficial to cache these rows instead of retrieving them from the disk over and over. Increasing the cache size in this case is a good idea.
However, if you run a warehousing or reporting database, then it’s unlikely that any row will be read twice in a short time. This means that there is no point in caching the data. Instead, we should make the caches smaller!
If you run OLTP, then the actual process of tuning the shared_buffers parameter should look like this:
Start with something like 1GB of shared buffer memory for your database
Check hits and misses with pg_buffercache
Add another 1GB of shared buffer memory
Check hits and misses again. The hits should increase at this point
Continue adding the memory until you see that your hit rates do not increase anymore
If you run OLAP or warehousing, then you can use the same reasoning to lower the cache memory size without breaking the system's performance. See our article about troubleshooting low cache hit ratio to learn more.
work_mem
The work_mem parameter should be set depending on the number of connections you configure in your database. Once you have this number, then start with
work_mem = TOTAL_RAM / #connections / 16
If you observe that many queries still spill to drive, then continue doubling the work_mem setting until your queries don’t spill often anymore.
maintenance_work_mem
Set the maintenace_work_mem parameter to 1GB initially. If you observe that your vacuuming or other background processes are too slow, then double the size.
temp_buffers
Set the temp_buffers setting to 2GB divided by the number of connections as a starting point. If you observe many queries creating temporary tables, then double the size.
Connections
Each connection consumes some memory. Having too many connections decreases the system's performance and consumes a lot of memory. Therefore, you should limit the number of connections and use a connection pooler where possible.
See our guide for configuring connection poolers to understand how to configure them.
Query Optimizations
It’s rather obvious that slow queries may affect the amount of free memory. Inefficient queries may read too much data (by scanning tables instead of using indexes), spill to disk (by using inefficient join strategies), or lower the cache hit ratio (by updating unused indexes).
Therefore, always optimize the queries. Analyze their join strategies, s-argable parameters, filters, spills to drive, and other aspects that lower the performance. Read on to understand how Metis explains everything you need to know to improve performance.
Indexes
Unused indexes may lower your free memory. Every time you update the data in a table, you may need to update the indexes as well. Even if the indexes are not used, they need to be in sync with the tables. This means that updating a row in a table may cause many more updates to be performed.
The general recommendation here is to remove all unused indexes. When looking for unused indexes, consider the following:
Why is the index unused? Maybe it should be used but you have a problem with a query. In that case, don’t touch the index, but fix the query instead
Is the index unused everywhere? Maybe it’s used in read-only replicas? It’s beneficial to keep the database configuration uniform between replicas so do not remove the index in that case.
Is the index unused? Maybe it’s used for some rare scenarios, like monthly reports. In that case, consider removing the index and only recreating it for the reports once a month if that helps.
If you’re sure the index is not used, then just drop it. If you observe performance degradation in some queries, then analyze their historical performance if they slowed down when the index was dropped. If that’s the case, then maybe they used the index after all.
Operating System Configuration
As mentioned before, your operating system configuration may affect how your database performs. The general recommendation is to disable memory overcommitting and the Transparent Huge Pages. Consult the documentation of your operating system to understand how to do that.
Cache Hit Ratio
In general, all steps to improve the cache hit ratio may improve the low free memory scenario. See our troubleshooting guide on the cache tuning.
Partitioning
Analyze your tables if it’s possible to partition them. There are many ways to do so and you can follow our partitioning guide to learn more.
Scaling
If nothing else helps, you may consider scaling the server. You can make the machine bigger (vertical scaling) or distribute the load (horizontal scaling). Start with the vertical scaling as it’s much easier. If that doesn’t help, then consider the horizontal scaling but keep in mind that this may require changes to the database clients.
How Metis Helps
Metis can help with many aspects along the way. Most importantly, Metis analyzes the queries and provides actionable insights on how to make them faster:
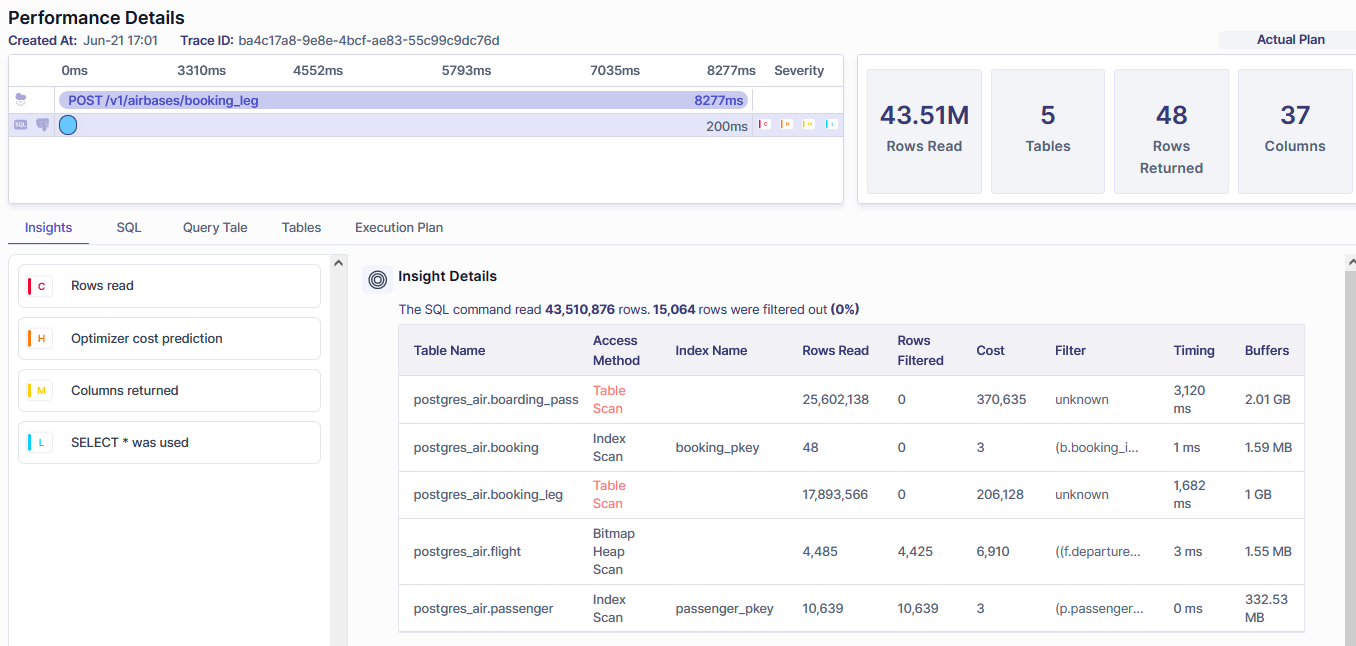
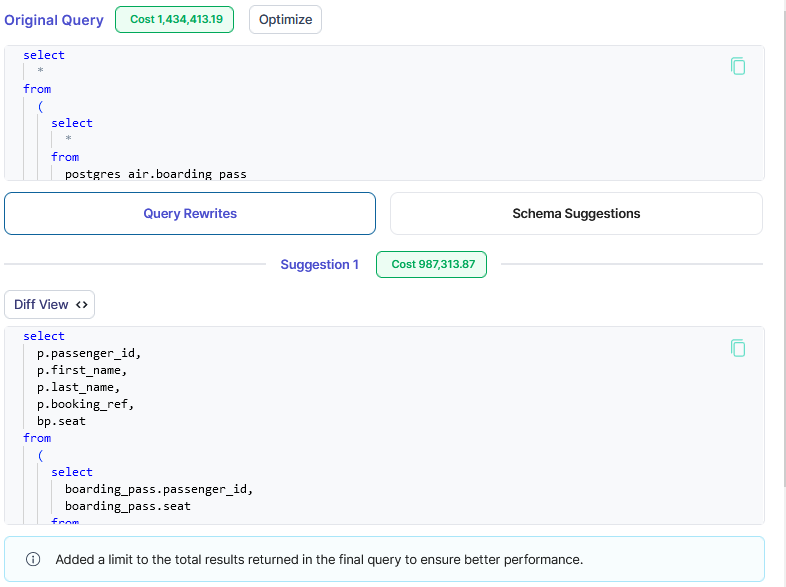
Metis uses artificial intelligence to rewrite your queries and then verifies if that helps:
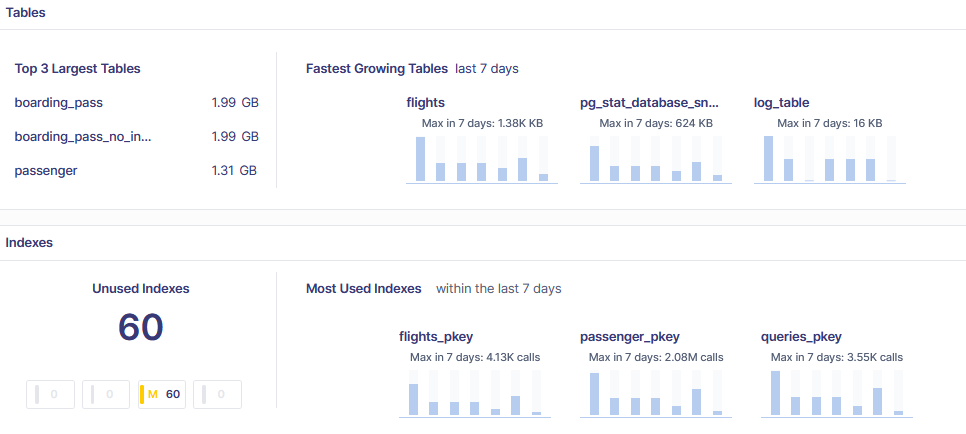
Metis can analyze your schemas, indexes, configurations, extensions, and everything that affects the database performance;
In short, Metis is the only database-oriented solution that can walk you through the optimization process.
Summary
Low free memory may be complex to debug. We need to understand that many moving pieces are interconnected. We need to analyze our operating system configuration, database configuration, and the workload we’re facing. Things are different for OLTP and OLAP systems, and there are no silver bullets. Fortunately, Metis shows everything you need to know, and this guide walks you through the optimization process. Use Metis and put your database on steroids!







