Requirements
- CLI that support UNIX styles commands
- git version > 2.0 (For me current version is 2.34.0)
- github.com account
Why use the command line?
All GUI tools for git have been built on top of CLI, also nowadays they’ve become very rich, but they lack functionality from the original CLI. For simple tasks it’s not a big deal, but for complicated one missing functionality start to become vital.
GUI can sometimes create a layer of abstraction for the user, that becomes only available only in this proprietary tool putting boundaries on choosing software freely.
Last, but not least CLI commands can be automatized using bash on your demand. (Combining several commands you can gain a stunning result) With GUI — you’re fully dependent on vendor updates.
What is GIT?
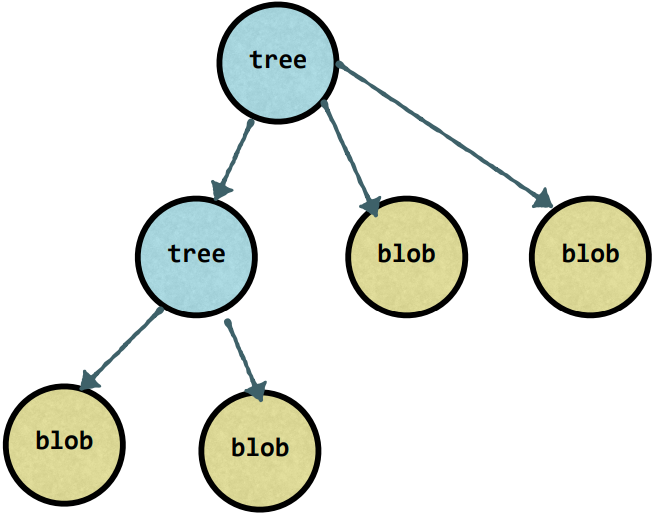
GIT — Distributed Version Control System
Let’s unpack this. Distributed — means that storing of data is the responsibility of several computers, not a single one. For example, the server, our computer and collaborator Bob’s computer. Distributing doesn’t mean that our data will be synchronized.
Version Control System — every object (in our case file) have an established state in time (version) and we can manage this state and go back and forward replaying it. (control system).
How does GIT store information?
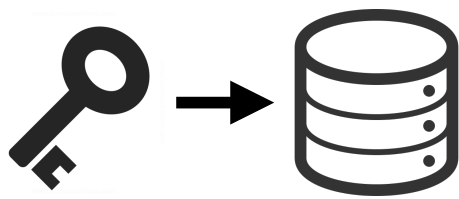
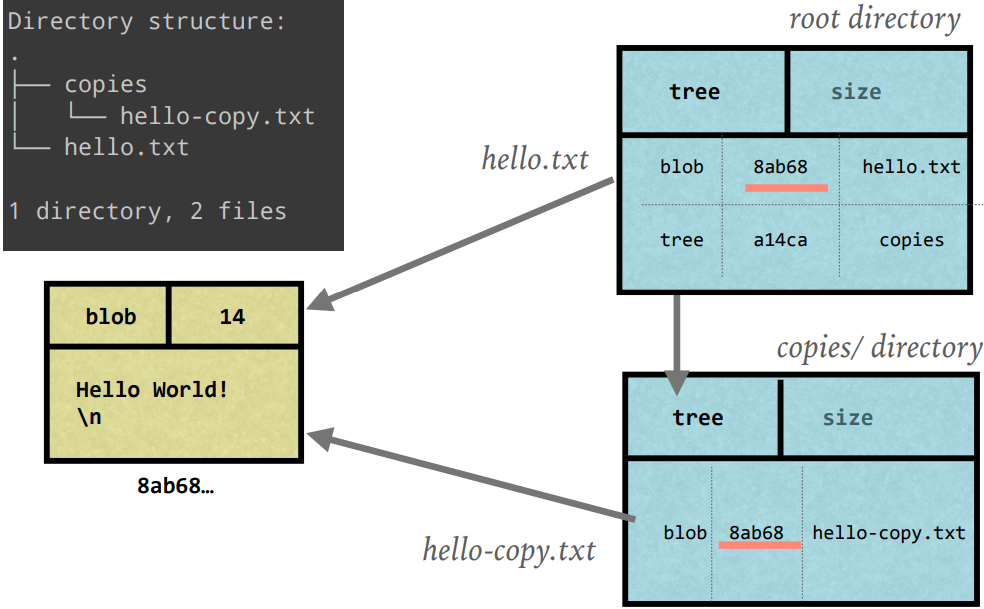
- At its core, GIT is like a key-value store.
- The Value = Data
- The Key = Hash of data
- Having keys, you can retrieve files.