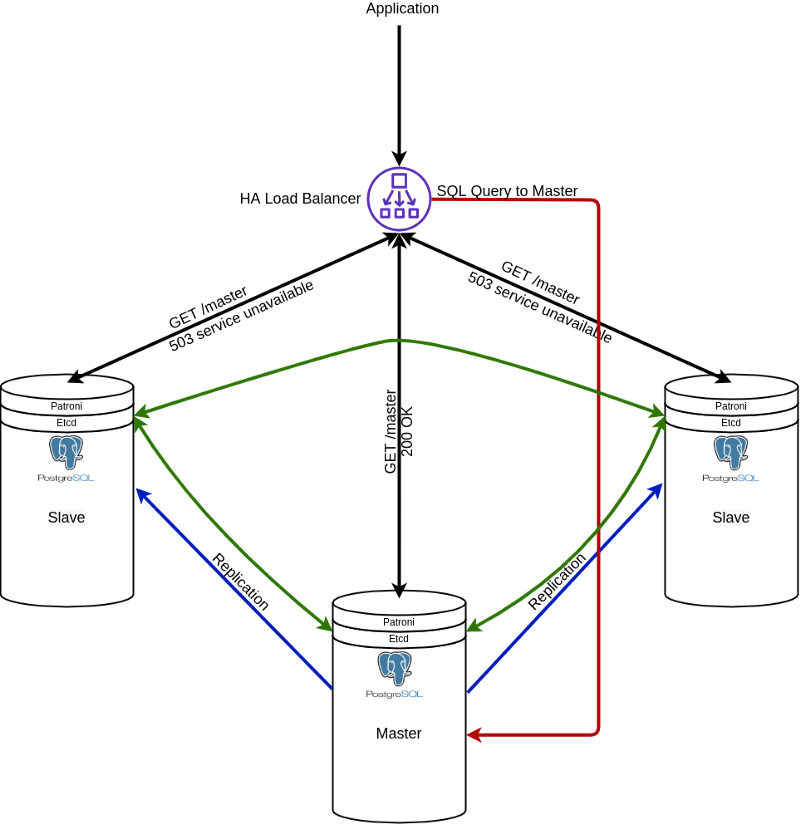
Alright, PostgreSQL cluster design has been done.
High available Celery
Actually, there is no HA for celery, celery works on each node independently and communicates with a message broker which is highly available. For Celery monitoring, there is application ‘Flower’.
HA message broker
Airflow supports two brokers: Redis and RabbitMQ.
As we are going to build an HA cluster, it requires a broker should be high available too or distributed over cluster nodes.
Initially, I decided to use Redis, because I am familiar with it. Then I found a utility from Netflix called Dynomite[3]. It looked nice to be used in my cluster. The description told it allows to build multi-master clusters. And I started to use it.
When everything was done I realized it didn’t work, because Redis had implemented new features in protocol. I had to give up using Netflix’s application.
RabbitMQ cluster
RabbitMQ supports high availability by default, also it has a web server to control the RabbitMQ cluster, you can see its status, stop, start and perform other actions on instances. For security reasons, it is not recommended to open access from the Internet.
DAGs synchronization
If you have a possibility to connect a shared volume to each of the three nodes, the further paragraph you can skip.
As we have a few nodes and each node has its own web server when a user is creating a new task, this new just created DAG will be saved on the same machine where this webserver works. Therefore it’s necessary to synchronize DAGs among all nodes in a cluster since workers can be switched over nodes or worked in parallel. For this role, I recommend using csync2[4] and crontab. From my side, I can explain why I have chosen csync2 + crontab. Initially, I saw the bundle lsync [5] + csync2 as an ideal. Let’s see, lsync can track changes on filesystem using inotify syscall, and then csync can synchronize these modified files.
There are many tools that allow syncing files between machines, but csync2 has an advantage — it can work in clusters with nodes more than two. Looks fine, doesn’t it? Further, while I was testing the solution, I found it was a bad idea.
lsyncd fails if csync2 cannot connect to a remote server, for instance, if one node is down. In this case, csync2 returns 1 and lsync fails. I didn’t manage to change this behavior. That’s why I decided to use crontab to run csync2 every minute instead of lsync.
If someone knows a better solution, please let me know.
So this is the end of part 1. See you in part 2, where we will consider the implementation and installation process step by step.
Sources:
[1] https://github.com/apache/airflow/
[2] https://github.com/bucardo/bucardo/
[3] https://github.com/Netflix/dynomite
[4] https://github.com/LINBIT/csync2
[5] https://github.com/axkibe/lsyncd