Part 2
Implementing the Airflow HA solution
For simplifying installing process, I will perform all actions under root. You should use a non-privileged user with sudo for installing. We’ll skip this question as well as many security aspects.
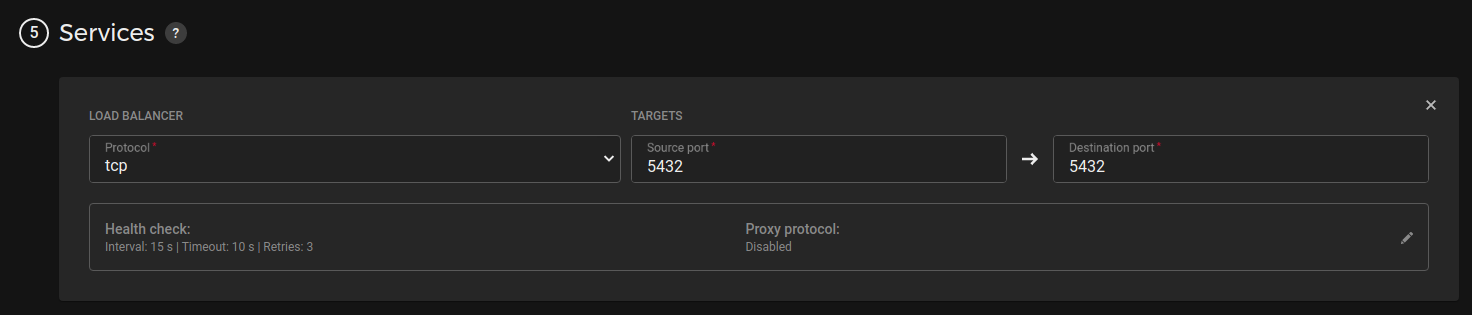
1.1 Installing etcd and patroni
Let’s start the installation process by installing the PostgreSQL cluster with Patroni.
Prepare a node for installing necessary packages: