






On July 12th 2022, after six months of deployment and testing, NASA will host a press conference and present the initial results of the James Webb Space Telescope. Five targets have been selected as the first wave of scientific observations and the publication of their images marks the official beginning of Webb’s science operations.
Success through Reliability — Webb Lesson 5
On July 12th 2022, after six months of deployment and testing, NASA will host a press conference and present the initial results of the James Webb Space Telescope. Five targets have been selected as the first wave of scientific observations and the publication of their images marks the official beginning of Webb’s science operations.

Artist’s impression of the James Webb Space Telescope, ready for action! (NASA) (source)
From a Site Reliablity Engineer’s perspective, this marks the moment when Webb moves from Day-1 operations to Day-2 operations.
What do I mean by this? During the lifecycle of developing new services, there are basically three stages , which we can metaphorically call “days”:
- Day 0 — This is the initial design and development of the service, from the collection of business requirements, creating a development plan, creating the initial MVPs and all the way to the actual creation of the service (including, of course, testing it in the proper environments).
- Day 1 — This is the moment the service goes live and can potentially start working. It’s the moment we click “deploy” and the solution gets pushed into the production environment. In theory, Day 1 could take a few minutes, but since we’re responsible people, we’ll stretch Day 1 out a bit, spending time and making an effort to be sure that everything is working properly before moving on to…
- Day 2 — This is the stage where our service is working properly and our customers are enjoying the fruits of our hard labour. At this point our solution is working in the production environment and we’re ready to solve any problems which might arise.

High level view of Day 0, Day 1, and Day 2 cycle
This cycle is repeated whenever we want to upgrade or update the service and have a day 0 to 1 to 2 process for the new features.
If we were buying a car then Day 0 would be everything from the moment we decided we wanted a new car through comparing models, arguing with sales representatives, getting financing for the car and finally walking out the door with the keys.
Day 1 in this metaphor would be the first few days of ownership, when we’re still figuring out which side of the car we put in fuel, how to set the radio for our favourite stations, and get to know how the engine sounds at different speeds. Day 1 can take a few hours or a few weeks, depending on how all sorts of things such as how different the new car is or how experienced we are as drivers.
Day 2 is, of course, our day-to-day usage of the car. Everything from traveling from point A to point B, filling up the car with fuel, cleaning the car, fixing flat tires, and dealing with other drivers on the road.
For the James Webb Space Telescope, Day-0 started back in 1995 when the initial planning for Hubble’s next generation successor began and continued for over 25 years of design, re-design, construction, testing, failures, re-re-design, re-construction, re-testing, successes, integration of all the pieces, sending to French Guinea, launching in December 2021, unfolding in deep space, arriving at a special spot in space called L2 and cooling down to the right temperature.
About six weeks after launch, Webb had finally completed its initial deployment and was ready for its engineering and scientific calibration, or day 1 work.
At the highest level of abstraction, three things happen during this time period, all of which have immediate parallels to the Day-1 work SREs do when a new service is deployed.
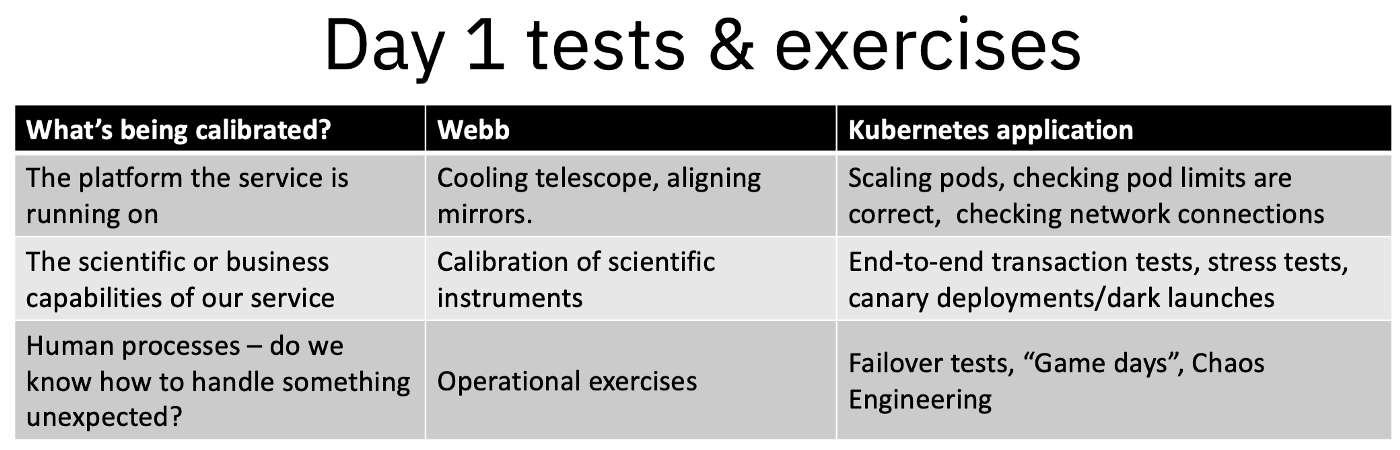
Types of calibration tests done by NASA engineers and SREs during Day 1 tests
The snazzy and flashy tests are often at the platform level — it’s much simpler to pronounce that the test was successful when the test has a simple “yes/no” result such as:
- Has the telescope cooled to -153 degrees Celsius (about -244 degrees Fahrenheit) or not?
- Does the Kubernetes service scale down to 0 and up to 3 pods or not?
In the (in)famous example of the Hubble Space Telescope, back in 1992, the image was technically better than any image taken from any previous telescope ever.

Initial Day-1 image from the Hubble Space Telescope (NASA/Wikipedia) (source)
From a purely technical engineering perspective, the initial calibration of Hubble was deemed a success. But from a scientific perspective, since the scientists were looking at a much more nuanced result that “yes, the telescope takes good pictures”, the results were a disappointment because they were not as sharp as they should have been.
One of the lessons NASA learned after their problems with Hubble was a closer alignment between engineers (who are operating the platform) and scientists (who are the consumers of the scientific capabilities). In the same way, one of the biggest differentiators between SREs and operators/sysadmins is the need for SREs to be involved in the business of the service they are responsible for and not remain at the technological layer.
For this reason a lot of attention has been given to the results of the scientific instrument calibration tests. Even though they are only designed to test whether the instruments work properly and not specifically to gather scientific data, some of the results have already been shared with scientists (and a smattering even with the general public) to enable them to assess the data.

Webb calibration image (NASA/CSA)
A similar SRE Day-1 practice is allowing a small group of users early access to the capabilities of the new product. The presumption is that this early group will be more patient when encountering unexpected issues and happier to cooperate with SREs to resolve them. This means that early issues will only affect a small (friendly) section of customers and not cause dissatisfaction if problems arise. Two common ways of allowing early access are:
- Canary Deployments: the solution is only made available to a specific subset of users — only those in a certain geography, only a certain class of users, only those who signed up as early adopters, only those in a specific department and so on. For all other users, it’s business as usual and they’ll continue using the old version of the product. This is a direct analogy to the “canary in the coal mine” which was used as an early warning to miners that the air was becoming dangerous. If the new feature is good for the canaries, then it can be deployed to everyone else.
- Dark Launches: the solution is technically deployed to all users, but it’s not visible to them — perhaps the menu option is hidden somewhere obscure, perhaps they need to register to get access to the new capability, perhaps they need to go to a new URL to access the new feature and so on.
While the end result is the same (limiting the number of users who have access to the new features), the choice between Canary Deployment and Dark Launch will depend on many factors beyond the scope of this article. A good rule of thumb is that Dark Launches will be a bit faster to roll out to all users, but are a bit more risky in exposing users to unexpected issues.
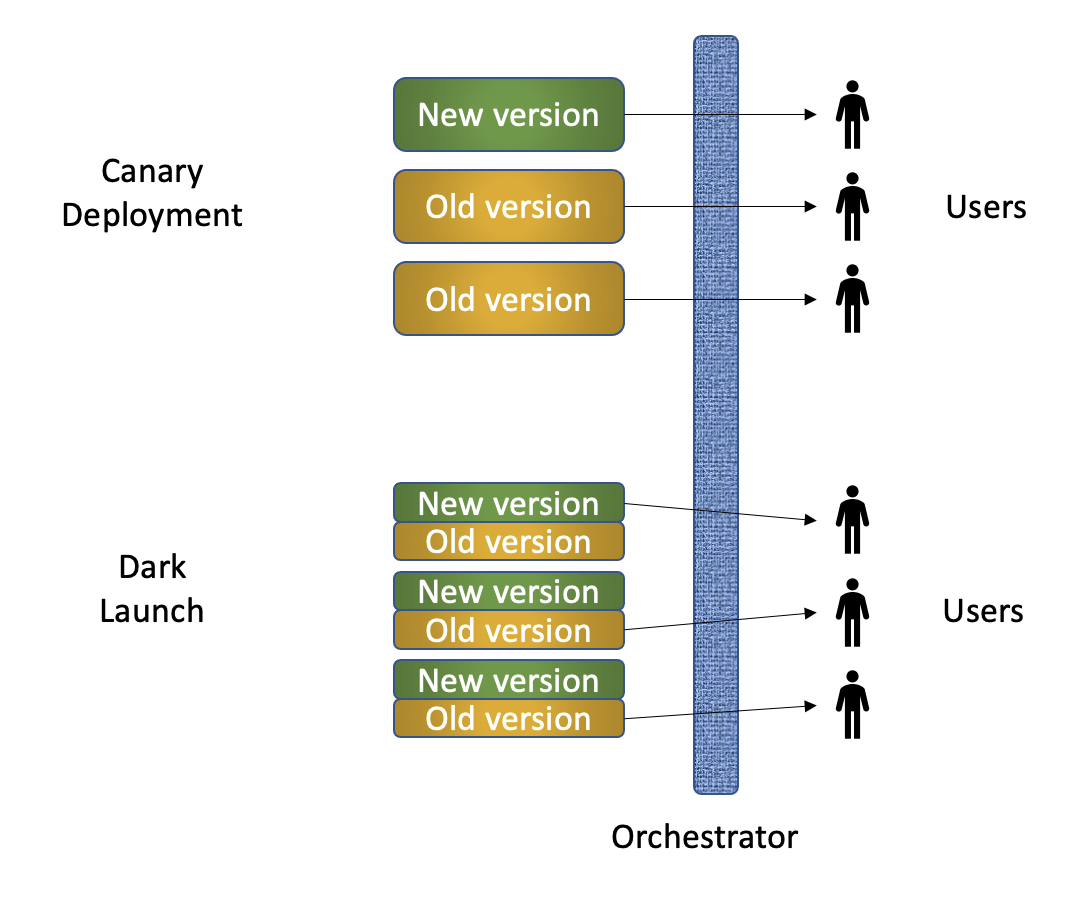
Diagram showing the difference between Canary Deployment and Dark Launches
In the case of the James Webb Space Telescope, NASA has announced five different scientific targets which are the “canaries” and represent a fine cross section of the types of scientific targets Webb will explore over the coming decade. One far away planet, two beautiful clouds of glowing gas (Nebula) and two exotic sets of galaxies.
The third thing which happens during Day-1 testing is exercising the humans who deal with Webb — What happens when there’s a problem? How do we deal with it? What’s the first step in the troubleshooting process? What happens next? Who do we talk to? Once we’ve solved the problem how do we make sure it stays solved?
All these processes need to be tried out and practiced during the engineering calibration stages so that, if a problem occurs during the time-sensitive scientific collection, Webb can be returned to normal as soon as possible.
SREs use “Game Days” and “Chaos Engineering” to replicate real word problems and try out different techniques to solve them. This point shows a major difference between SREs in a digital world, where it’s easy to crash and relaunch a virtual component and Webb’s engineers, who only have one real, physical, space telescope and can’t perform any tests which would risk its survival.
Another difference is that SREs aspire to have many small launches of minor changes, each of which is limited in size and risk, while NASA’s engineers only have one James Webb Space Telescope. So SREs would have a cycle of day 0, 1 & 2 each time a new feature is released which is why a new deployment should be business as usual and not a reason for a major press conference.
While a new deployment of a digital service may be a commonplace ocurance for an SRE, the announcement that the Webb space telescope is operational is going to be an unique event. I’m excited to see the results of the Day-1 testing and to see what magnificent discoveries Webb has in store for us during the next few years of Day-2 Operations.

Two of Webb’s first targets — a group of galaxies called Stephen’s Quintet and the Carina Nebula — as photographed by the Hubble Space Telescope (ESA/NASA) (source)

Two of Webb’s first targets — a group of galaxies called Stephen’s Quintet and the Carina Nebula — as photographed by the Hubble Space Telescope (ESA/NASA) (source)
You can read more about IBM’s Day-2 Operations for RedHat OpenShift here and about Canary Deployments and Dark Launches as part of the Cloud Service Management & Operations online course.
Follow the publication of Webb’s first images at https://webb.nasa.gov/
If you liked this article please clap here and share elsewhere. And here’s a list of more articles like this:
| Part | Article | |
| I | The 1201 program alarm | |
| II | Glenn’s flight | |
| III | Functional vs non-functional requirements | |
| IV | RACI | |
| V | ChatOps | |
| VI | SRE & Transparency | |
| VII | Operational Scorecards | |
| VIII | MVP vs PoC | |
| IX | DevSecOps Quarantine | |
| X | Reliability | |
| XI | Day-2 Operations | |
| XII | Flying to the Moon is like developing on your laptop | |
| XIII | Three minutes without breathable air | |
| XIV | If Neil Armstrong were your engineer, you wouldn't need this! | |
| XV | Computer-aided responses and reflexes | |
| XVI | Overcoming chaos on the way to the Moon | |
| XVII | Managing an Agile product launch — over Christmas | |
| 2020 | Lunar Landing Lessons from 2020 | |
| XVIII | Flying to the Moon from the Backroom — Mission Control | |
| Lunney | Glynn Lunney — SRE Leadership | |
| STS-1 | The Mightiest Monolith | |
| Collins | Michael Collins — Carrying The Fire | |
| STS-2 | 4th of July Fireworks — A Balanced Action Plan | |
| STS-3 | Testing and Proofs of Concept — the Shuttle Approach and Landing Tests | |
| Webb-1 | The James Webb Space Telescope — Making 300 points of failure reliable | |
| Webb-2 | The James Webb Space Telescope — Success through Redundancy | |
| Webb-3 | Gyros and Gimbals, oh my! — The James Webb Space Telescope Reliability Lessons | |
| Webb-4 | Known Unknowns — Webb Struck by Meteoroid! | |
| Webb-5 | Day 2 Operations with the James Webb Space Telescope |
For future lessons and articles, follow me here as Robert Barron or as @flyingbarron on Twitter and Linkedin.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Robert Barron
SRE Architect, IBM
@flyingbarron


User Popularity
20
Influence
2k
Total Hits
1
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

#/media/File:Hubble_First_Light,_First_Released_Image_(STScI-1990-04a).png){kind=link}
Only registered users can post comments. Please, login or signup.