Tradeoffs are hard. Think about the time when you had to choose between two equally compelling options - (a) addressing technical debt or (b) pushing out that long-awaited feature release, and risk breaking production. Or when your team couldn’t agree on where to draw the line on improving request latency versus shipping a major new update.
If this sounds familiar, count yourself as part of the Eternal Conundrum Club of Reliability Engineering. It’s fairly easy for us as humans to communicate the impact of a new feature release as opposed to the utility of cleaning up a part of the system that would cause us to worry less. This is because feature releases are more often than not, tied with business impact, ie. potential to generate revenue, but it’s a little harder to quantify and justify the business impact resulting from engineering reliability into your offering.
Alas, without a healthy balance between release velocity and reliability engineering, you’re going to end up with not only unhappy customers but also unhappy teams. Often, teams realize this problem too late - when business outcomes have already taken a hit.
Hello Error Budgets!
The key to resolving this dilemma is to add more context. This can support your decision making by helping you understand the tradeoffs between release velocity and reliability engineering. Error budgets are one such example of a quantifiable measure that can aid this decision making in real-time. Once we accept that risk cannot be avoided, but can be managed, it becomes easier to understand the utility and application of error budgets.
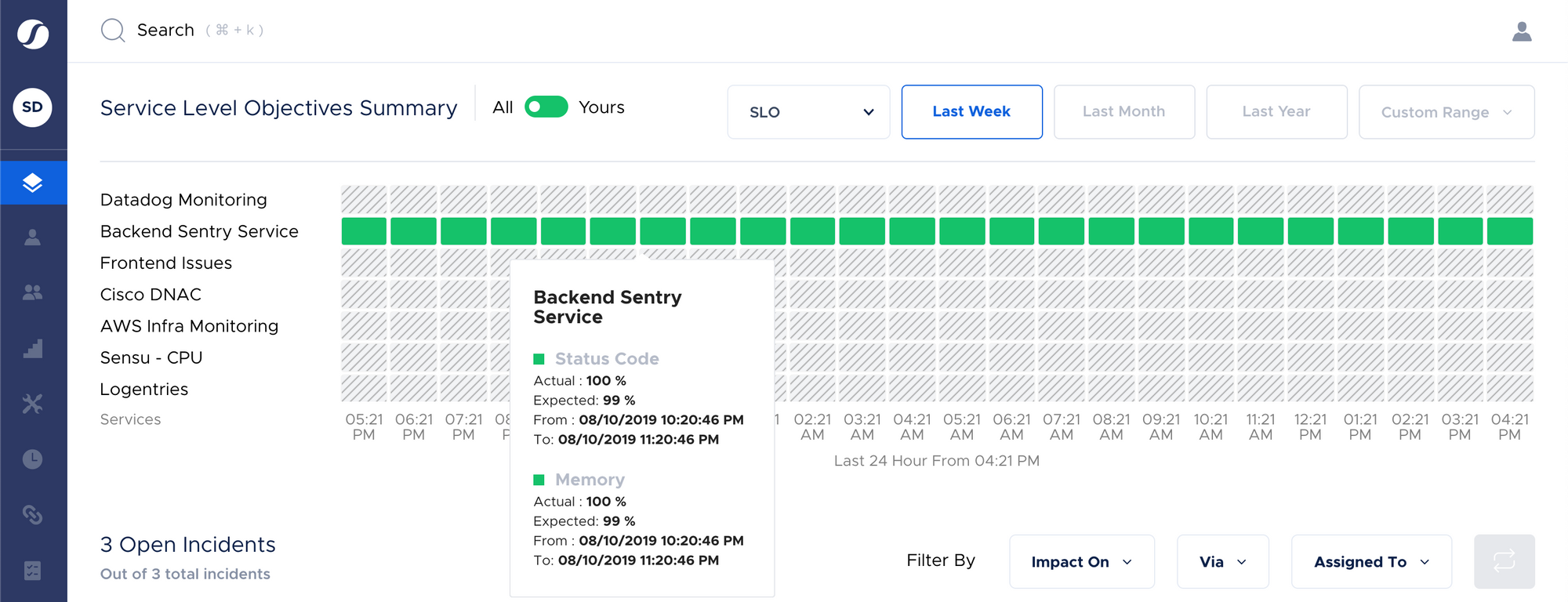
Error budgets tie back to the concept of SLIs, SLOs, and SLAs. Here’s a quick outline of what they mean -
Service Level Agreement (SLA) is a promise between you and your customers on the acceptable availability of your system over a certain time period and it outlines business implications and compensation in the event of a breach. Essentially, not maintaining your SLA is going to hurt your bottom line.
Service Level Objectives (SLOs) are just another variation of SLAs which are owned internally by the product and engineering teams. SLOs are typically stricter than SLAs to ensure that an SLO breach precedes an SLA breach. Every customer-impacting service must have an SLO which will serve as its quantitative reliability measure. This is defined in alignment with business stakeholders as it is imperative for them to be on top of the SLAs they can promise to customers. They also need to quantify and explain to their engineering team about the cost attached to downtime and its adverse effects on the business reputation.