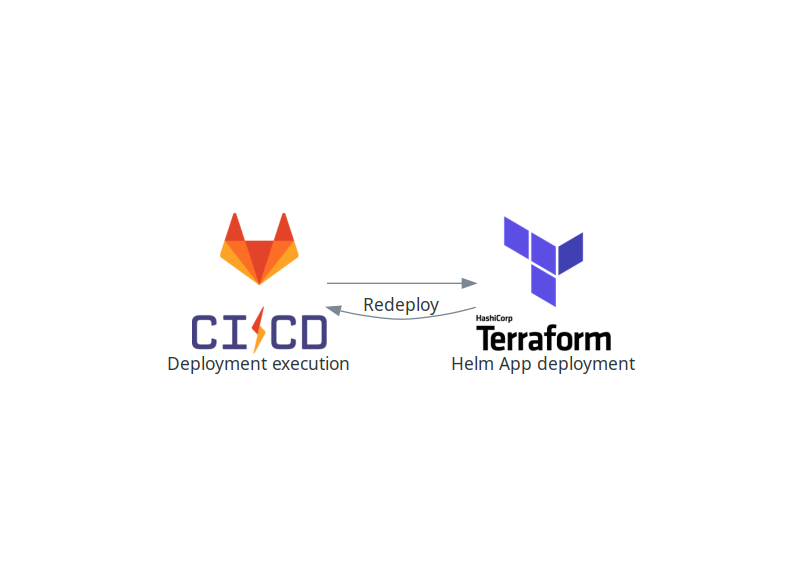
Legacy deployment
The final legacy deployment consists of the following steps:
- Deployment execution (GitLab CI) — responsible for setting up and executing step 2.
- Cloud resources orchestration (Terraform) — creates all OpenStack resources (VMs, virtual router, networks, subnets, floating IPs, security groups, key pairs) and executes steps 3, 4, and 5.
- Configuration management (Ansible) — installs all required packages, creates configuration files, and sets up Docker Compose templates.
- Execution of Docker Compose application (Ansible)
- Initial application data provisioning (Ansible) — LDAP users, DB accounts …