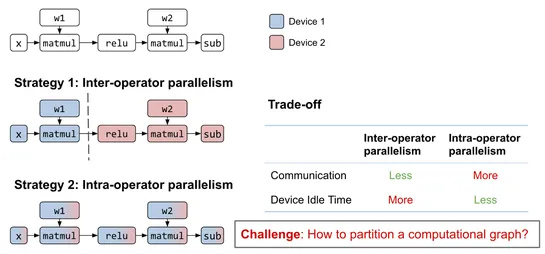
Efficiently Scale LLM Training Across a Large GPU Cluster with Alpa and Ray
This post presents how two open-source frameworks,Alpa.aiandRay.io, work together to achieve the scale required to train a 175 billion-parameter JAX transformer model with pipeline parallelism. They enable the training of LLMs on large GPU clusters, automatically parallelizing computations and optim.. read more