Local AI Engineering with Ollama


Run, understand, customize, fine-tune, and build agentic apps on your own hardware
Join us

Run, understand, customize, fine-tune, and build agentic apps on your own hardware

🚨 €𝟭.𝟯 𝗕𝗜𝗟𝗟𝗜𝗢𝗡. That's how much the 𝗘𝗨 is investing in 𝗔𝗜, 𝗰𝘆𝗯𝗲𝗿𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆, 𝗮𝗻𝗱 𝗱𝗶𝗴𝗶𝘁𝗮𝗹 𝘀𝗸𝗶𝗹𝗹𝘀. But here's the real question: 👉 𝙄𝙨 𝙮𝙤𝙪𝙧 𝙞𝙣𝙛𝙧𝙖𝙨𝙩𝙧𝙪𝙘𝙩𝙪𝙧𝙚 𝙧𝙚𝙖𝙙𝙮 𝙛𝙤𝙧 𝙬𝙝𝙖𝙩'𝙨 𝙘𝙤𝙢𝙞𝙣𝙜 𝙣𝙚𝙭𝙩? The European Commission has just sent a powerful message to organizations across Europe: cybersecurity is no longer optio..

Businesses are shifting from Generative AI to Agentic AI systems because modern enterprises need more than content generation; they need AI that can think, plan, make decisions, and execute tasks autonomously. Agentic AI enables smarter workflow automation, faster decision-making, reduced manual effort, and improved operational efficiency across industries. As businesses focus on scalability and intelligent automation, Agentic AI is emerging as the next evolution of enterprise AI solutions.

Want to build Agentic AI System? Explore this guide on Agentic AI systems, their types, architecture, and enterprise use cases.


Agentic AI pentesting is transforming security by moving beyond traditional, point-in-time assessments to continuous, autonomous attack simulation. It can map attack surfaces, chain vulnerabilities, and validate real risks at scale. While it won't replace human pentesters, it will amplify their capabilities, enabling faster, deeper, and more effective security testing.


Why big tech interviewers are tired of seeing the exact same blueprint, and how to fix it in 60 seconds.
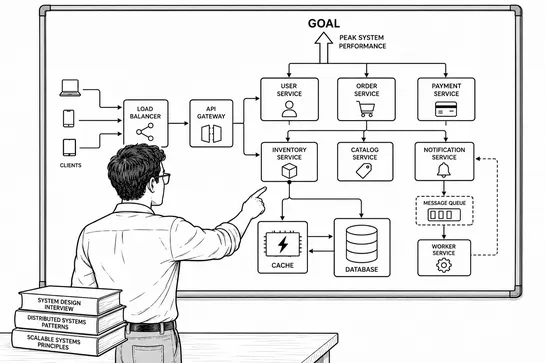

CI/CD stands for Continuous Integration and Continuous Delivery (or Continuous Deployment). It’s the practice of automating the process of integrating code changes, testing them, and delivering them to production — often dozens or hundreds of times a day.

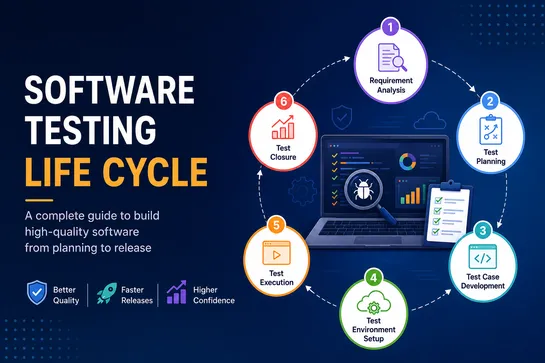
The Software Testing Life Cycle (STLC) is a structured process that helps teams ensure software quality through different testing phases such as requirement analysis, test planning, test case development, environment setup, test execution, and test closure. It enables organizations to identify defects early, improve test coverage, and deliver stable applications with greater confidence.
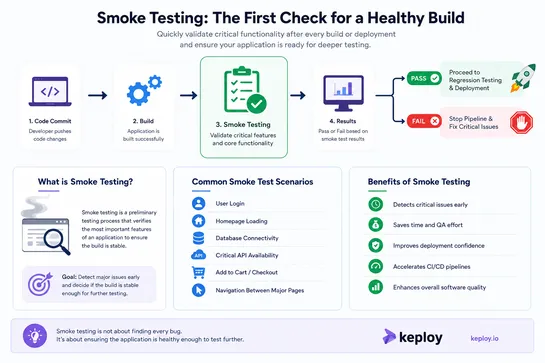
Smoke testing is a quick testing method used to verify whether the core functionality of an application works properly after a new build or deployment. It helps teams detect critical issues early, avoid wasting QA effort on unstable builds, and improve deployment confidence in CI/CD pipelines.