Measuring Developer Productivity with Amazon Q Developer and Jellyfish
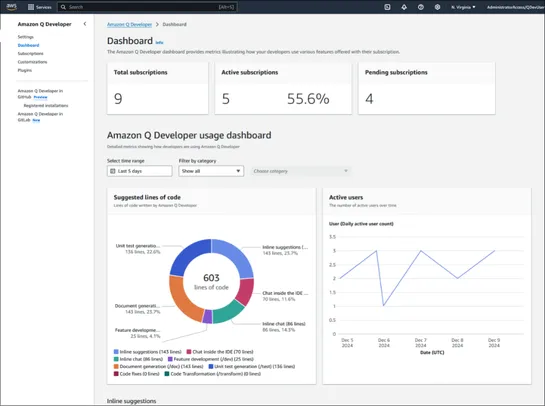
Amazon Q Developer now plugs into Jellyfish. Teams get a clearer view of how AI fits into the real flow of work—prompt usage, code adoption, PR throughput. Not just surface stats. The setup pipes data from AWS S3 straight into Jellyfish’s analytics engine. It tags AI users, tracks velocity gains, an.. read more