What kubectl debug doesn’t tell you: The silent evidence gap
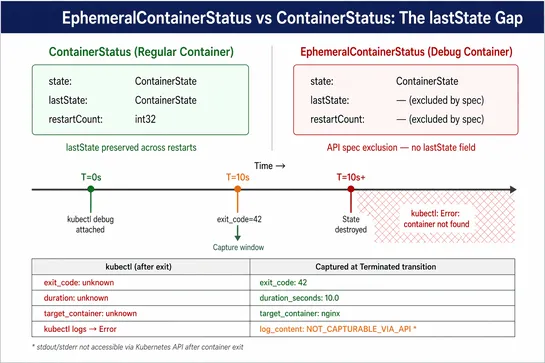
kubectl debugsessions leave almost no forensic trace: by design,EphemeralContainerStatushas nolastStateorrestartCount, so the exit code, session duration, target container, and debugger logs disappear from the Kubernetes API the moment anything else updates the pod. That breaks incident handoffs (th.. read more