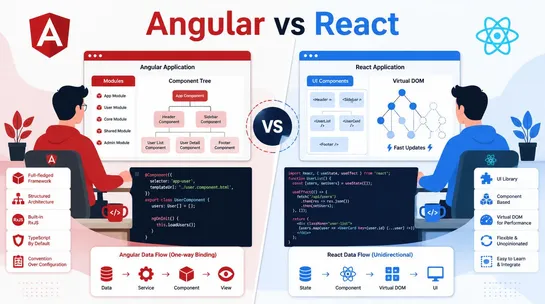
Angular vs React: Which Framework Is Better for Web Development?
Angular vs React: discover the main differences, performance, and use cases to choose the best framework for modern web development projects in 2026.
Join us

Angular vs React: discover the main differences, performance, and use cases to choose the best framework for modern web development projects in 2026.

You know the drill:build a product roadmap in Jira, create your product backlog, review it, update the user stories, come up with a sprint goal before the meeting, and finally, review every story to decide which ones need to be completed this sprint. Easier said than done, right? Well-planned sprint..

🚨 Not all 𝗱𝗶𝗴𝗶𝘁𝗮𝗹 𝗰𝗲𝗿𝘁𝗶𝗳𝗶𝗰𝗮𝘁𝗲𝘀 are created equal. From 𝗗𝗩, 𝗢𝗩, 𝗘𝗩 𝘁𝗼 𝗺𝗧𝗟𝗦 𝗰𝗹𝗶𝗲𝗻𝘁 𝗰𝗲𝗿𝘁𝘀 and 𝗰𝗼𝗱𝗲 𝘀𝗶𝗴𝗻𝗶𝗻𝗴, each plays a different role in your security posture. 🔐 Encryption is just the beginning: → Identity validation → Trust chains (Root → Intermediate → Leaf) → Secure software delivery → Zero Trust..

