Terraform Production Readiness Cheatsheet

Terraform working isn’t enough. Learn what it takes to make it production-ready — from backend design to security and automated pipelines.
Join us


Terraform working isn’t enough. Learn what it takes to make it production-ready — from backend design to security and automated pipelines.




")
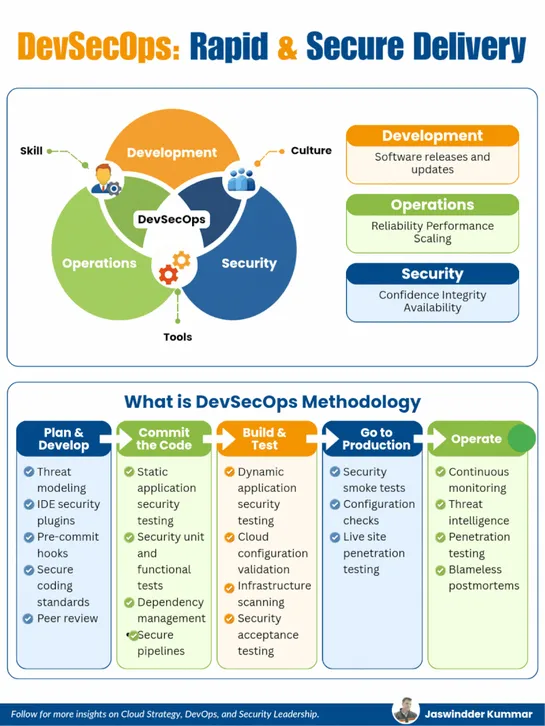
If security is your last step, you’re already too late. This guide shows how to build a DevSecOps pipeline where security is continuous, automated, and invisible to delivery speed.

The article catalogs obfuscation methods:HTML entities,SVG in an object,display:none, JavaScript decoders, custom encodings, andAES‑256. It coversmailtoobfuscation, redirects (302/301,.htaccess), interaction-gated reveals, accessibility caveats, and ahoneypot-based spam-statistics system... read more
SQLite packsJSONextraction, expression indexes,FTS5full-text search,CTEs, window functions, andWALinto a single file. It enforcesstrict tables, supportsgenerated columns, and indexes JSON expressions for fast semi-structured queries... read more

