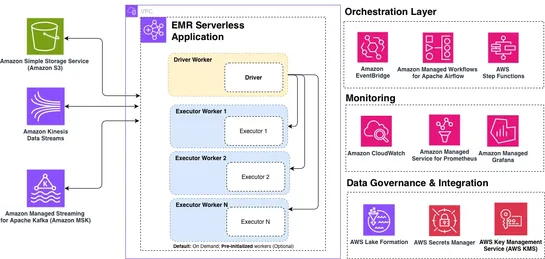
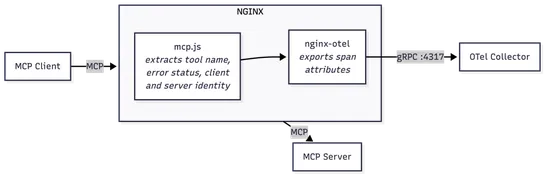
AI Isn't Replacing SREs. It's Deskilling Them.
This post discusses the impact of AI on the role of Site Reliability Engineers (SREs) by drawing parallels to historical research on automation. It highlights the risk of deskilling and never-skilling for SREs who heavily rely on AI tools for incident response. The post also suggests potential appro.. read more