Introducing Claude Opus 4.8
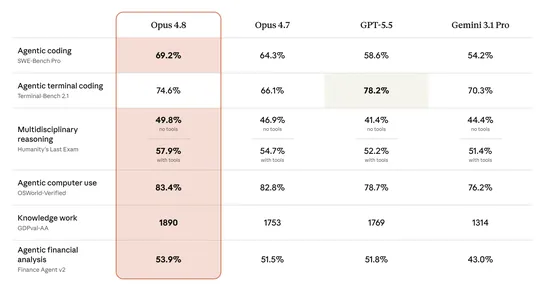
Claude Opus 4.8 delivers top-tier performance with honest and powerful collaboration, outpacing prior models and GPT-5.5 across multiple benchmarks. Opus 4.8's cutting-edge abilities and improved judgment set a new standard for enterprise AI, enhancing reliability and reasoning quality, ready for im.. read more