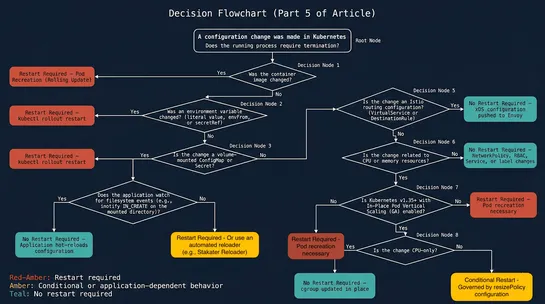
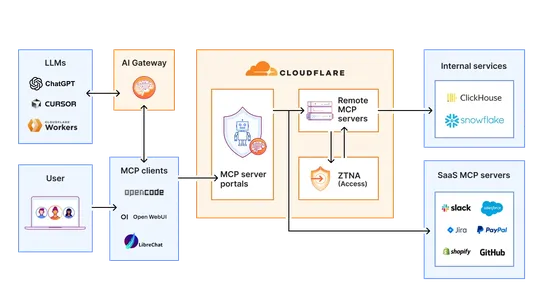
How GitHub uses eBPF to improve deployment safety
GitHub hosts its own source code on github.com, creating a circular dependency. To mitigate this, GitHub maintains mirrors of its code and built assets. By using eBPF, GitHub can selectively monitor and block calls that create circular dependencies in their deployment system... read more