Building an Event-Driven Network Policy Engine with eBPF and Cilium
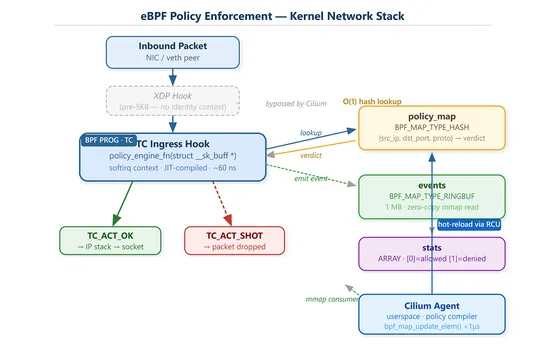
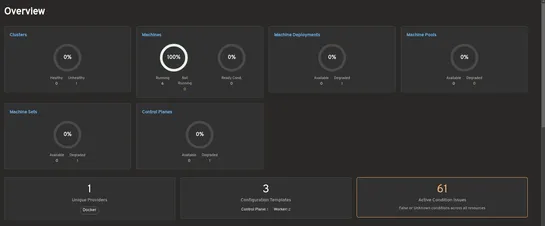
Running iptables -L on a node in a 500-node cluster can cause the terminal to freeze due to kube-proxy writing 40,000–60,000 rules across various chains. Conntrack tracks each flow with a global spinlock, becoming a bottleneck past 80,000 connections per second. Cilium replaces this path entirely by.. read more