






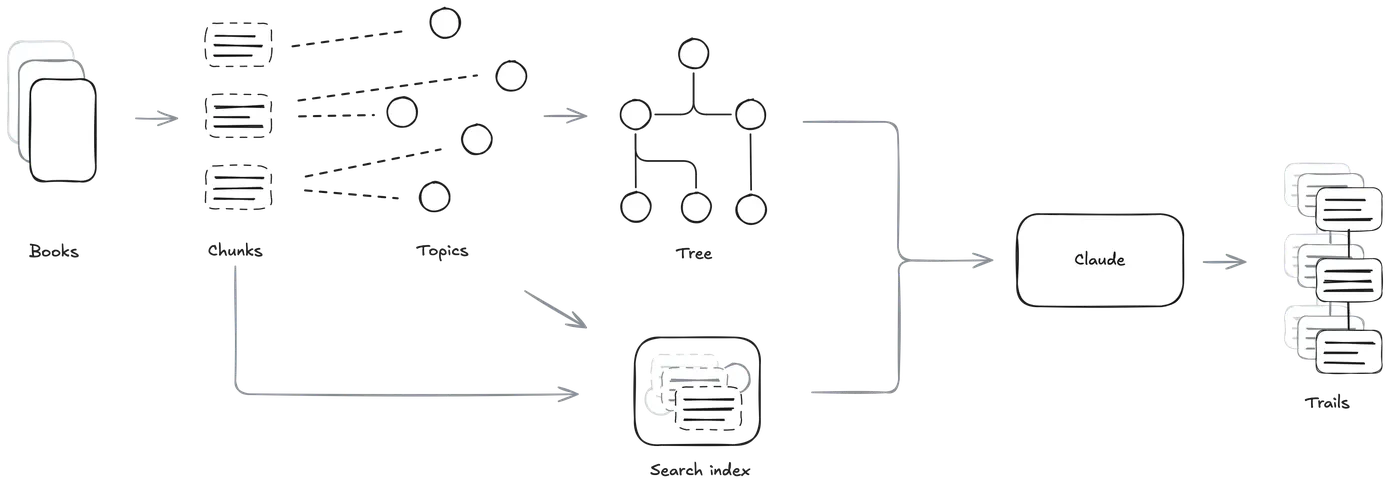
A custom LLM agent, built with Claude Code and some hard-working CLI tools, chewed through 100+ nonfiction books by slicing them into 500-word semantic chunks - and then threading excerpt trails by topic.
Under the hood: Chunk-topic indexes lived in SQLite. Topic embeddings flowed through UMAP for clustering. A persistent server kept the embedding model warm, saving cold-start pain. Then Leiden partitioning, run recursively, built a layered topic tree from that mess of ideas.


