






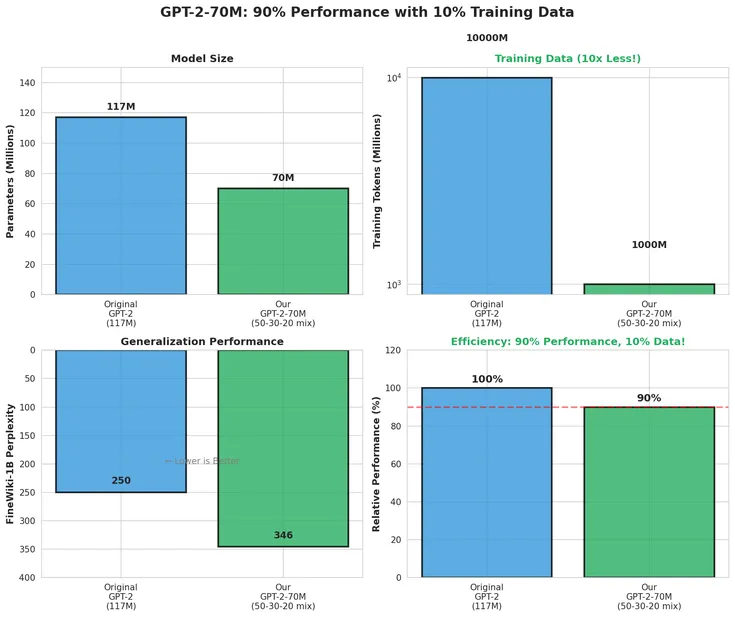
Researchers squeezed GPT-2-class performance out of a model trained on just 1 billion tokens - 10× less data - by dialing in a sharp dataset mix: 50% finePDFs, 30% DCLM-baseline, 20% FineWeb-Edu.
Static mixing beat curriculum strategies. No catastrophic forgetting. No overfitting. And it hit 90%+ of GPT-2’s benchmark scores at 50× lower training cost.


