What It Is?
Machine Learning is the learning in which a machine can learn on its own without being explicitly programmed. It is an application of Al that provide the system with the ability to automatically learn and improve from experience. Here we can generate a program by integrating the input and output of that program. One of the simple definitions of Machine Learning is “Machine Learning is said to learn from experience w.r.t some class of task T and a performance measure P if learners performance at the task in the class as measured by P improves with experiences.”
Sometimes Artificial Intelligence and Machine Learning are considered as same but they are somehow different from each other.
Difference b/w AI & Ml:
AI:
1- Al stands for Artificial intelligence, where intelligence is defined acquisition of knowledge. Intelligence is alsodefined as the ability to acquire and apply knowledge.
2- The aim is to increase the chance of success and not accuracy.
3- It works like a computer program that does smart work
4- The goal is to simulate natural intelligence to solve complex problems.
5- Al is decision making.
ML:
1- ML stands for Machine Learning which is defined as the acquisition of knowledge or skill.
2- The aim is to increase accuracy, but it does not care about success.
3- It is a simple concept machine that takes data and learns from data.
4- The goal is to learn from data on certain tasks to maximize the performance of machines on this task.
5- ML allows systems to learn new things from data.
Terminologies of Machine Learning:
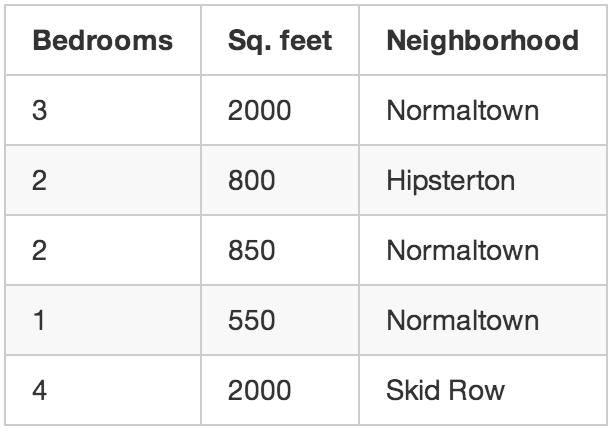
• Model: A model is a specific representation learned from data by applying some machine learning algorithm. A model is also called a hypothesis.
• Feature: A feature is an individual measurable property of our data. A set of numeric features can be conveniently described by a feature vector. Feature vectors are fed as input to the model. For example, in order to predict a fruit, there may be features like colour, smell, taste, etc.
Note: Choosing informative, discriminating and independent features is a crucial step for effective algorithms. We generally employ a feature extractor to extract the relevant features from the raw data.
• Target (Label): A target variable or label is the value to be predicted by our model. For the fruit example discussed in the features section, the label with each set of input would be the name of the fruit like apple, orange, banana, etc.
• Training: The idea is to give a set of inputs(features) and its expected outputs(labels), so after training, we will have a model (hypothesis) that will then map new data to one of the categories trained on.
• Prediction: Once our model is ready, it can be fed a set of inputs to which it will provide a predicted output(label).
The figure shows clearly the above concepts: