







In this tutorial, you’re going to build a real time spam detection web application. This application will be built with Python using the Flask framework and will include a machine learning model that you will train to detect SMS spam.
We will work with the Agora messaging API so that you’ll be able to classify SMS messages sent to the phone number you have in your Agora account.
Prerequisites
In order to follow and fully understand this tutorial, you’ll need:
- Python 3.6 or newer. The Anaconda distribution includes a number of useful libraries for data science.
- A basic knowledge of Flask, HTML, and CSS.
- A basic understanding of building machine learning models.
- Agora free virtual number.
AGORA API ACCOUNT
To complete this tutorial, you will need an Agora API account. If you don’t have one already, you can sign up today and start building. Once you have an account, you can find your API Key and API Secret at the top of the Agora API Dashboard.
This tutorial also uses a virtual phone number. To get one, go to numbers and search for one that meets your needs.

Set Up a Python Virtual Environment
We need to create an isolated environment for various Python dependencies unique to this project.
First, create a new development folder. In your terminal, run:

Next, create a new Python virtual environment. If you are using Anaconda, you can run the following command:

Then you can activate the environment using:

If you are using a standard distribution of Python, create a new virtual environment by running the command below:

If you are using a Windows computer, activate the environment as follows:

Regardless of the method you used to create and activate the virtual environment, your prompt should have been modified to look like the following:

Install Required Packages
Next, you’ll install all the packages needed for this tutorial. In your new environment, install the following packages (which includes libraries and dependencies):

Here are some details about these packages:
- jupyterlab is for model building and data exploration.
- flask is for creating the application server and pages.
- lightgbm is the machine learning algorithm for building our model
- matplotlib, plotly, plotly-express are for data visualization
- python-dotenv is a package for managing environment variables such as API keys and other configuration values.
- nltk is for natural language operations
- numpy is for arrays computation
- pandas is for manipulating and wrangling structured data.
- regex is for regular expression operations
- scikit-learn is a machine learning toolkit
- wordcloud is used to create word cloud images from text
After installation, start your Jupyter lab by running:

This opens the popular Jupyter lab interface in your web browser, where you are going to carry out some interactive data exploration and model building.
Build and Train the SMS Detection Model
Now that your environment is ready, you’re going to download the SMS training data and build a simple machine learning model to classify the SMS messages. The spam dataset for this project can be downloaded here. The datasets contain 5574 messages with respective labels of spam and ham (legitimate). More about the dataset can be found here. With this data, we will train a machine learning model that can correctly classify SMS as ham or spam. These procedures will be carried out in a Jupyter notebook, which from our file directory is named ‘project_notebook’
Exploratory Data Analysis (EDA)
Here, we will apply a variety of techniques to analyze the data and get a better understanding of it.
Import Libraries and Data
The necessary libraries for this project can be imported into project_notebook.ipynb as follows:
The spam dataset located in the dataset directory named spam.csv can be imported as follows:

Next, we get an overview of the dataset:

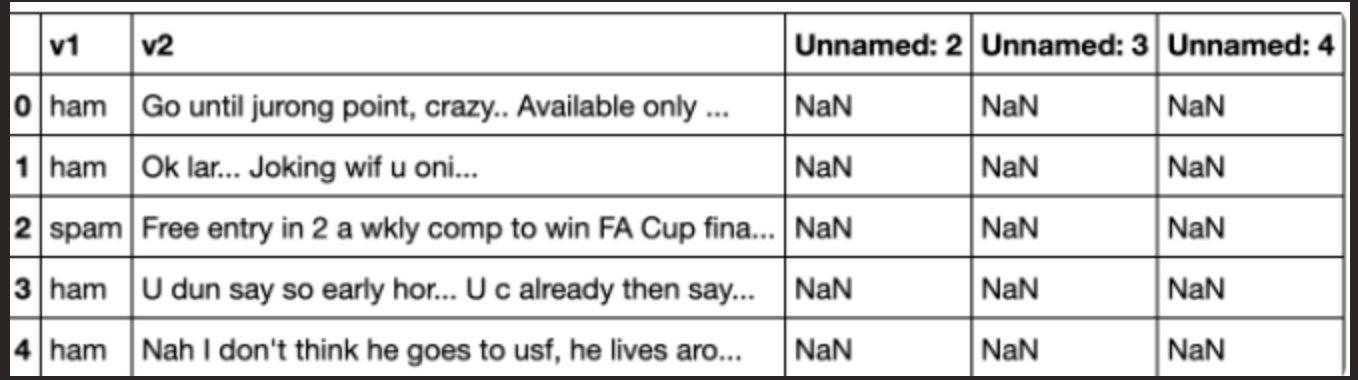
The dataset contains 5 columns. Column v1 is the dataset label (“ham” or “spam”) and column v2 contains the text of the SMS message. Columns “Unnamed: 2”, “Unnamed: 3”, and “Unnamed: 4” contain “NaN” (not a number) signifying missing values. They are not needed, so they can be dropped as they are not going to be useful in building the model. The following code snippet will drop and rename the columns to improve understandability of the dataset:


Let’s look at the distribution of labels:


We have an imbalanced dataset, with 747 messages being spam messages and 4825 messages being ham.

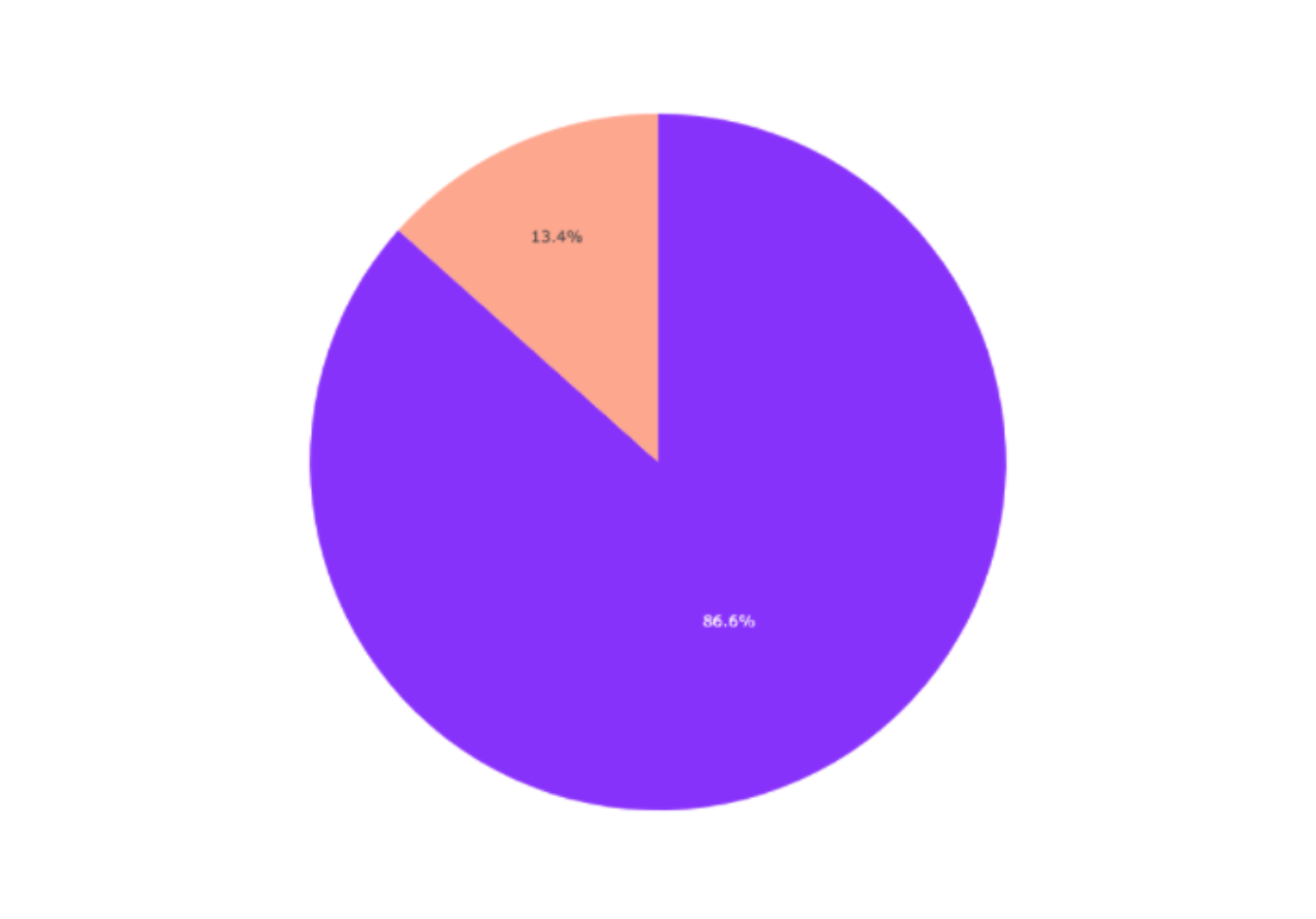
The spam makes up 13.4% of the dataset while ham composes 86.6% of the dataset.
Next, we will delve into a little feature engineering. The length of the messages might provide some insights. Let’s take a look:




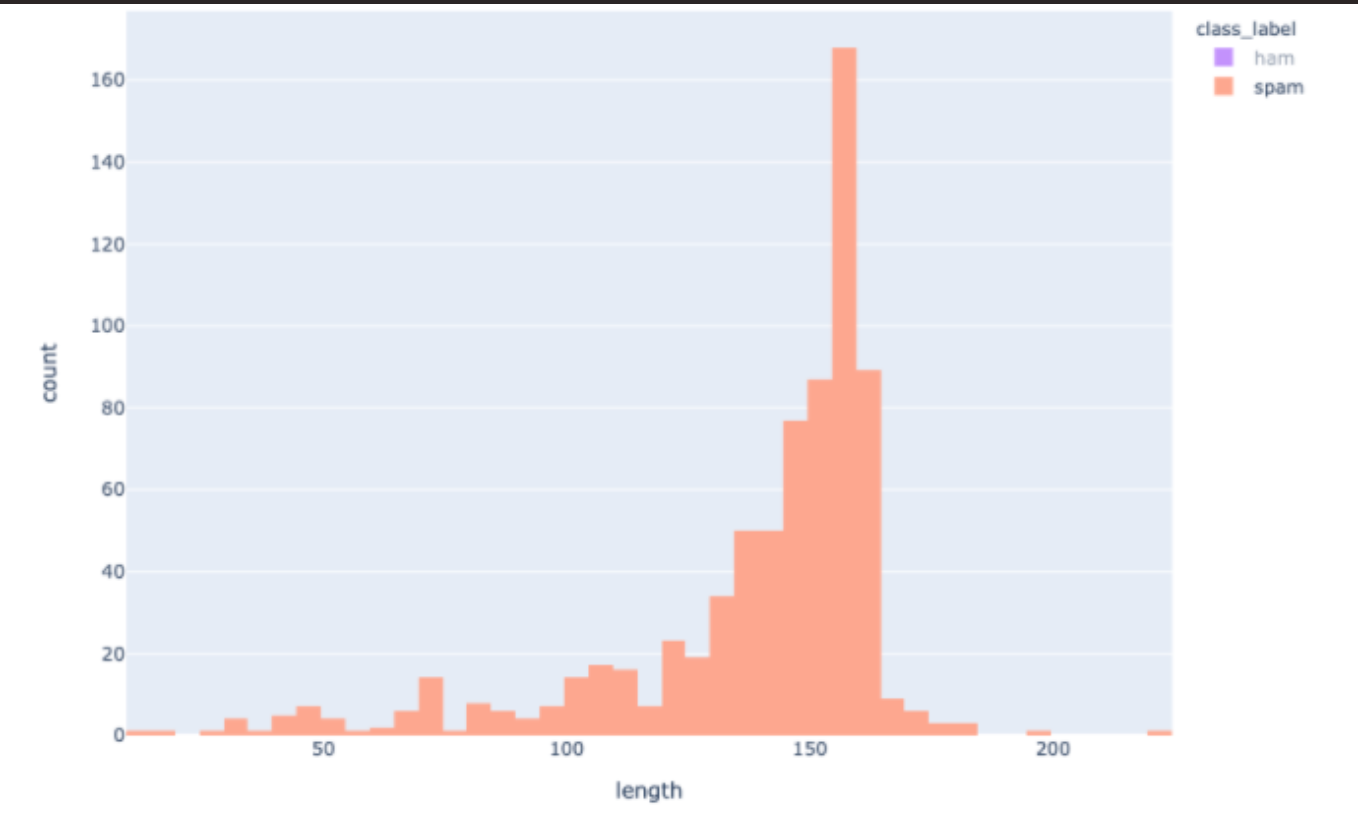
It can be seen that ham messages are shorter than spam messages as the distribution of ham and spam message lengths are centered around 30–40 and 155–160 characters, respectively.
Having a view of the most common words used in spams and hams will help us understand the dataset better. A word cloud can give you an idea of what kind of words are dominant in each class.
To make a word cloud, first separate the classes into two pandas data frames and add a simple word cloud function, as shown below:

Below is the code that displays a word cloud for spam SMS:


Preprocess the Data
The process of converting data to something a computer can understand is referred to as pre-processing. In the context of this article, this involves processes and techniques to prepare our text data for our machine learning algorithm
First, we’ll convert the label to numeric form. This is essential before model training, as deep learning models need data in numeric form.

Next, we will process the message content with Regular Expressions (Regex) to keep email and web addresses, phone numbers, and numbers uniform, encode symbols, remove punctuation and white spaces, and finally convert all text to lowercase:

Going forward, we’ll remove stopwords from the message content. Stop words are words that search engines have been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query such as “the”, “a”, “an”, “in”, “but”, “because” etc.

Next, we will extract the base form of words by removing affixes from them. This called stemming, as it can be illustrated as cutting down the branches of a tree to its stems. There are numerous stemming algorithms, such as:
- Porter’s Stemmer algorithm
- Lovins Stemmer
- Dawson Stemmer
- Krovetz Stemmer
- Xerox Stemmer
- N-Gram Stemmer
- Snowball Stemmer
- Lancaster Stemmer
Some of these stemming algorithms are aggressive and dynamic. Some apply to languages other than English and the text data size affects various efficiencies. For this article, the Snowball Stemmer was utilized due to its computational speed.

Machine learning algorithms cannot work with raw text directly. The text must be converted into numbers — more specifically, vectors of numbers. Let’s split the messages (text data in sentences) into words. This is a requirement in natural language processing tasks where each word needs to be captured and subjected to further analysis. First, we create a Bag of Words (BOW) model to extract features from text:

Let’s take a look at the total number of words:


Now plot the top 10 common words in the text data:


Next, we will implement an NLP technique — term frequency-inverse document frequency — to evaluate how important words are in the text data. In short, this technique simply defines what a “relevant word” is. The tfidf_model created from this NLP technique will be saved (serialized) to the local disk for transforming the test data for our web application later:


The shape of the resulting dataframe is 5572 by 6506. In order to train and validate the performance of our machine learning model, we need to split the data into training and test dataset respectively. The training set should be later split into a train and validation set.
The split ratio for the validation set is 20% of the training data.
Model Building
We will be utilizing a machine learning algorithm known as LightGBM. It is a gradient boosting framework that uses tree based learning algorithms. It has the following benefits:
- Faster training speed and higher efficiency
- Lower memory usage
- Better accuracy
- Support of parallel and GPU learning
- Capable of handling large-scale data
The performance metric for this project is the F1 score. This metric considers both precision and recall to compute the score. The F1 score reaches its best value at 1 and worst value at 0.


From this iteration, it can be seen that the Max Depth of six (6) has the highest F1 score of 0.9285714285714285. We will further perform a random grid search for the best parameters for the model:

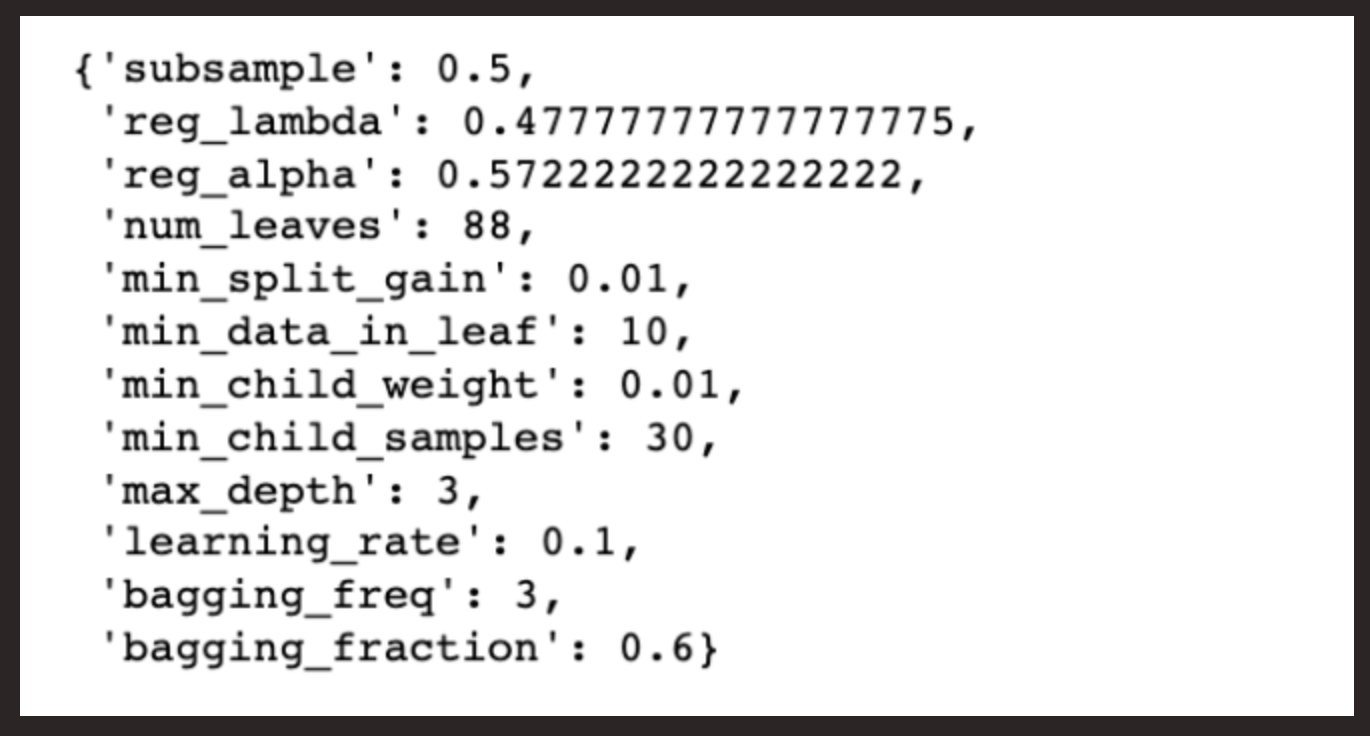
We’ll use the best parameters to the train the model:
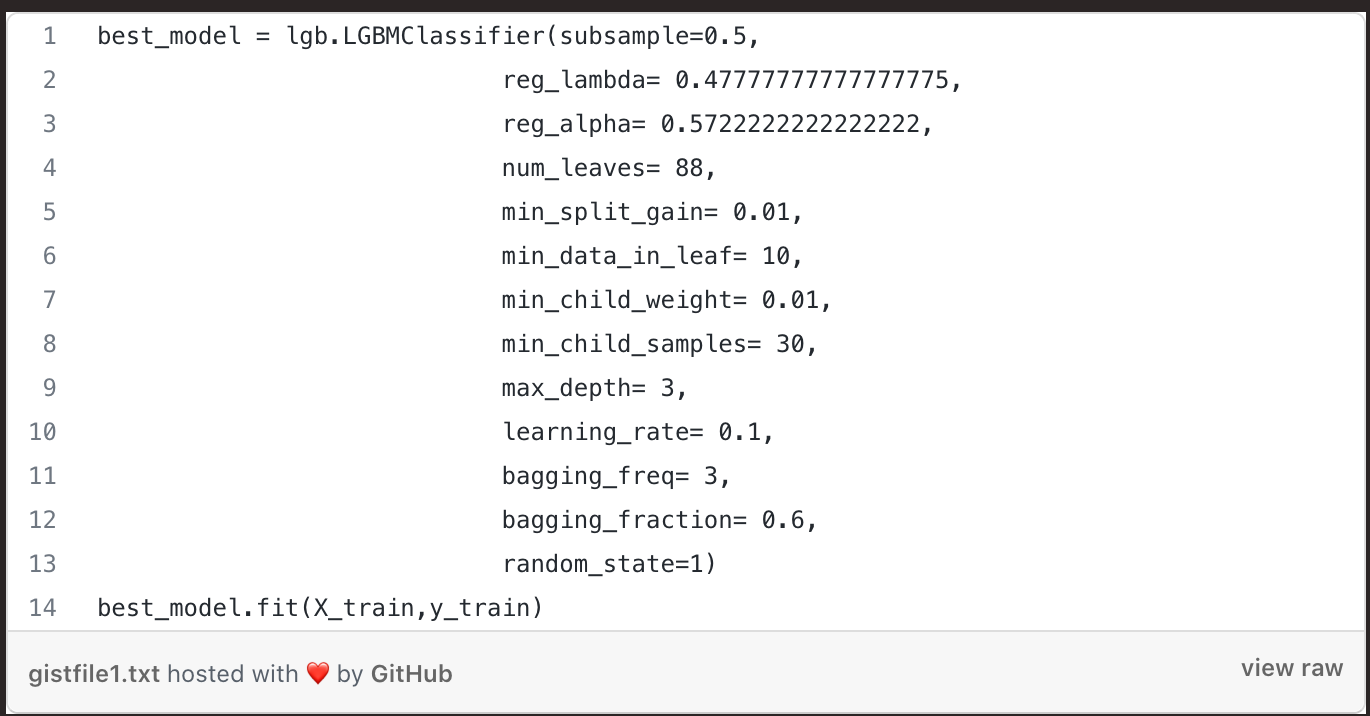

Let’s check the performance of the model by its prediction:


As a last step, we’ll do a full training on the dataset so our web app can make predictions for data it hasn’t seen. We’ll save the model to our local machine:

RTM Messaging
Since this is not a simple video call application, it will require some way for the director to control the participants. For this, we will use the agora_rtm package. This package allows you to send real-time data between everybody in the channel. The agora_rtc_engine package is built on top of agora_rtm. The difference is that RTM allows you to send any data, while RTC makes it easy to send video and audio data. For this application, only the director can send RTM messages, and the participants can only receive them. There are three types of functions we need to allow the director to have:
- Mute or unmute audio.
- Enable or disable video.
- Send out a list of active users.
To mute a user, the director sends out a channel-wide RTM message in the format “mute uid”, where “uid” is replaced with the specific uid of the user to be muted. On receiving this message, the participant checks if this uid is their uid. If it is, then the user mutes themselves. Unmuting, disabling and enabling video works the same way, except for using the keywords “unmute uid”, “enable uid”, and “disable uid”.
The slightly trickier part is the active users. Normally, if you’re using Agora, you would display all the broadcasters in that call. But in this case, some of them are in the lobby, and they should not be displayed to the viewers. To handle this, we use RTM messages again to send all the users that should be displayed. The format is “activeUsers uid,uid,uid”, where “uid” is replaced with the specific uid of the active users.

Conclusion
With that, we come to the end of this tutorial. You can try other SMS examples to see the outcome. I’m sure you can already think of all the amazing possibilities and use cases of this new knowledge. You can integrate this spam filtering into HR software, chatbots, customer service, and any other message-based application.
Thank you for reading!
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Adesina Abdulrahman
@adesinaabdulra9

User Popularity
28
Influence
3k
Total Hits
1
Posts


Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.