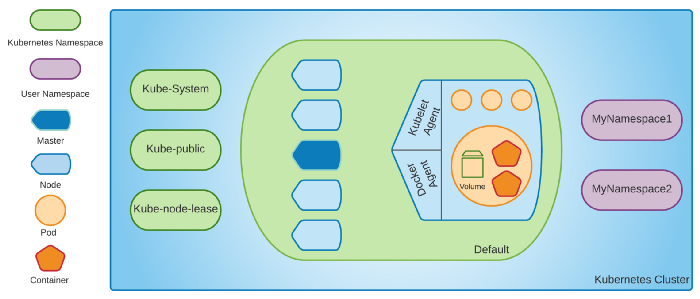
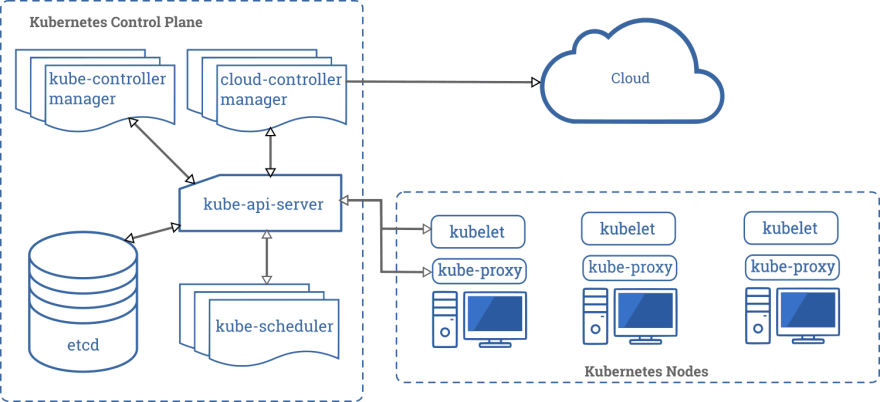
First one is responsible for managing the entire cluster and latter are responsible for hosting applications (containers).
Control plane decides on which worker node run each container, checks health state of a cluster, provides an API to communicate with cluster and many more. If one of the nodes will go down and if some containers were running on that broken machine, it* *will take care of rerunning those applications on other nodes.
Inside control plane we can find several, smaller components:
- kube-api-server — it’s responsible for providing an API to a cluster, it provides endpoints, validates requests and delegates them to other components,
- kube-scheduler — constantly checks if there are new applications (Pods, to be specific, the smallest objects in K8s, representing applications) and assign them to nodes,
- kube-controller-manager — contains a bunch of controllers, which are watching a state of a cluster, checking if a desire state is the same as current state and if not they communicate with kube-api-server to change it; this process is called control loop and it concerns several Kubernetes objects (like nodes, Pod replicas and many more); for each K8s object there is one controller which manages its lifecycle,
- etcd — it’s a reliable key-value store database, which stores configuration data for the entire cluster,
- cloud controller manager — holds controllers that are specific for a cloud providers, it’s available only when you use at least one cloud service in a cluster.
Also another component, that is not mentioned on a above picture, but is very important, is DNS. It enables applications inside the cluster to be able to communicate with each by specific (human-readable) names, and not IP addresses.
Apart from the control plane each Kubernetes cluster *can have one or more *workorder nodes on which application are running. To integrate them with K8s each one of them has:
- kubelet — is responsible of managing Pods inside the node and communicating with control plane (both components talk with each other when a state of a cluster needs to be changed),
- kube-proxy — take care of networking inside a cluster, make specific rules etc.
Kubernetes Objects
In the previous section I’ve mentioned something called Kubernetes Object, so let’s quickly look on what are they.
As mentioned before K8s provides an abstraction of an infrastructure. And to interact with a cluster we need to use some kind of the interface that will represent a state of it. And these are the Kubernetes objects, all of them represent a state of entire system. They are usually defined as a YAML files so that they can be saved under version control system and has an entire system declaratively described, which is very close to Infrastructure as Code approach.
There are several types of objects, but I want to mention only couple of them, which are the most important:
- Pods — as mentioned before, Pods are the smallest Kubernetes objects that represents an application. What is worth mentioning, Pods are not containers. They’re wrapper for one or more containers, which contains not only working application but also some metadata.
- Deployments — are responsible for a life cycle of Pods. They take care of creating Pods, upgrading and scaling them.
- Services — take care of networking tasks, communication between Pods inside a cluster. The reason for that is because Pod’s life is very short. They can be created and killed in a very short time. And every time the IP address can change so other Pods inside cluster would need to constantly update addresses of all depended applications (service discovery). Moreover there could be a case that are more than one instances of the same application inside the cluster — Services take care of load balancing a traffic between those Pods.
- Ingress — similar to Services, Ingress is responsible for networking, but on a different level. It’s a gateway to a cluster so that someone/something from external world can enter it based on rules defined in Ingress Controller.
- Persistent Volumes — provide an abstract way for data storage, which could be required by Pods (e.g. to save some data permanently or in cache).
- ConfigMaps — they holds key-value data that can be injected to Pods, for example as a environment variable, which allows to decouple an application from its configuration.
Apart from standard types of objects Kubernetes offer to create own Custom Resources, which allows to create either new versions of existing objects (with different behaviour) or brand new resource which will cover different aspect. They are widely used in something called Operator pattern and example of such would be a database operator which periodically do backups of databases (more examples of operators can be found on OperatorHub.io). With operators you can easily customize infrastructure to your needs and building the entire ecosystem on top of the Kubernetes.
Features of Kubernetes
I hope that now you understand a primary problem that Kubernetes is trying to solve. But this is not everything, there are more aspects of software engineering that it is addressing.
Scalability
One of the most important features of Kubernetes, that was already partially mentioned, is that it allows to scale number of application instances based on CPU usage (horizontal auto-scaling).
This is one of the cloud fundamental concept that depending on how busy an application is (how much of CPU it requires) K8s could decide to run additional instances of the same Pod to prevent low latencies or even crushes.