Bug Hunting, the Tedious Way
We are abstracting away the details of the payment process as this will not change the overall logic of the application. At this level, we have a working application that allows users to make reservations but as you know, in software development, bugs and errors are inevitable. We need to be able to detect and fix them as soon as possible. This is why all the science behind testing and quality assurance is so important. However, tests may not cover all the possible scenarios.
Now the application is packaged in a container and deployed to a Kubernetes cluster in production. The application ran without any problem, until receiving a request from a user who was complaining about an ambiguous error with a product order. Back to logs, the only error found was a 404 logline.
Not Found: /shop/process_transaction/5c89b4cc-f3d0-42a6-ab05-2b1c784906aa/
"POST /shop/process_transaction/5c89b4cc-f3d0-42a6-ab05-2b1c784906aa/ HTTP/1.1" 404 12660
Despite the error, the customer received a confirmation email containing the order details. This kind of error can be reported by the customer using a ticket system and issue tracker or an equivalent service.
Based on the above log, the code is raising the Http404("Product does not exist") but at the same time, the product exists in your database. The log is not telling us too much apart that there's a problem. In this case, we will need to manually debug to see what's going on. Depending on the complexity of your application, this could take us some time.
The least desirable aspect is that, in some cases, you must deploy a newer version with additional logging. You may think of some remote development tools that could make the process faster. These tools allow you to access a container, change the code, and test. However, there are some problems here:
- If you're running multiple pods, and thus multiple containers, you'll need to add logs to each one. For example, if your application uses tens of containers, you'll need to add logs to all of them. This is tedious.
- Not all developers have access to production environments. To start a simple debug, you’ll need the agreement of the production team in most cases.
- Updating code in production can carry significant risks, such as network problems and database inconsistencies.
- Containers are ephemeral and immutable. You can update your code in production, but you can't guarantee it will remain. When Kubernetes restarts a container, its state will revert to how it was configured in the image.
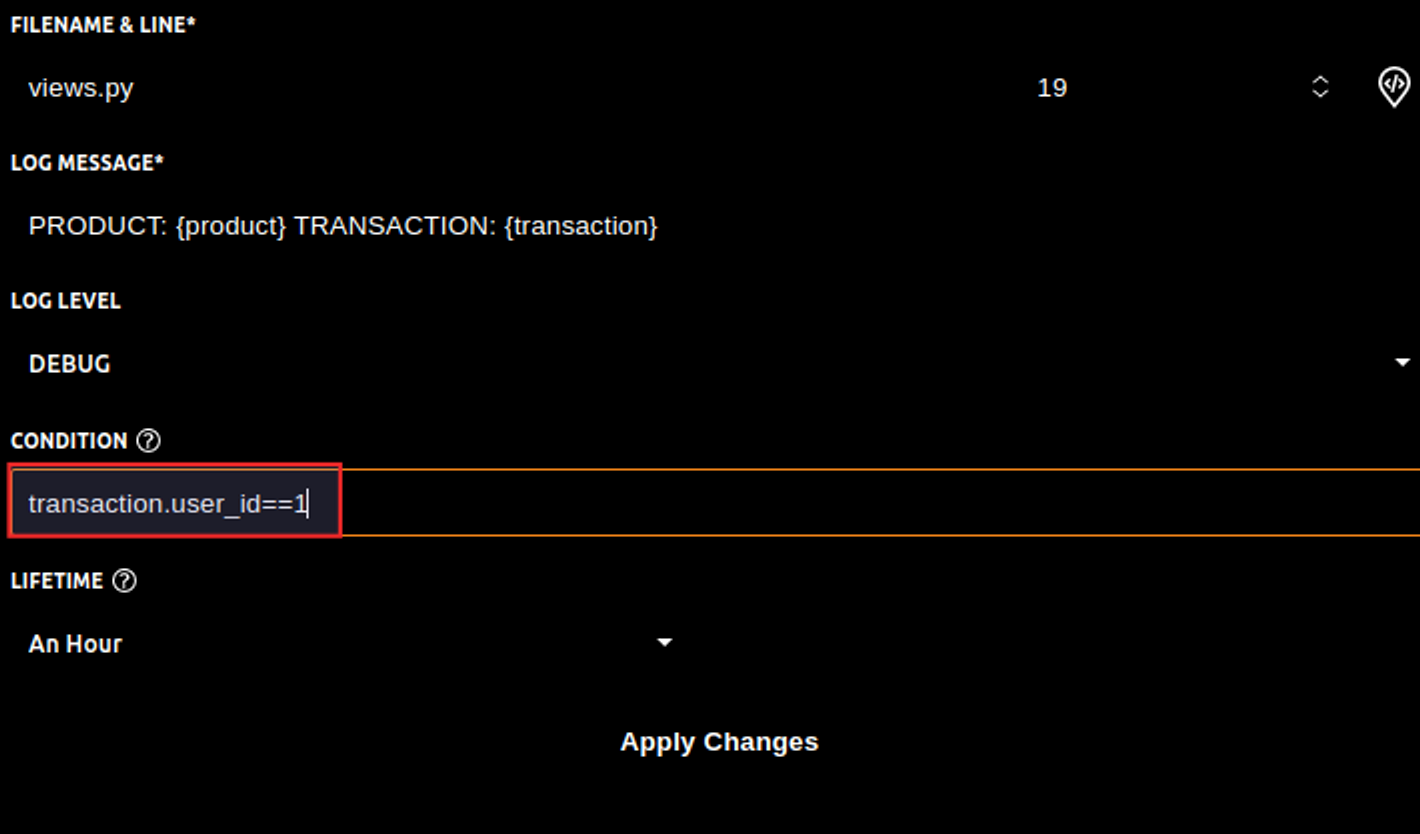
The good news is that Lightrun can help without exposing you to any of these risks as it allows you to go through a complete troubleshooting cycle with the help of its features, such as dynamic logging.
This is what we are going to see in detail in the next section.
Bug Hunting, The Lightrun Way
Let's see how Lightrun can help us save tremendous amounts of time when debugging.
It is worth noting that Lightrun enables debugging in production without changing any code. Its integration into remote production is required only once.
You may have multiple configuration files, one per environment, this is our case.
In the production settings, start by creating a free account on Lightrun, get your key, and add the following lines to your production configuration: