What is AWS Lake Formation ?
AWS Lake Formation is a service that makes it easy to set up a secure data lake in days. A data lake is a centralised, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. A data lake lets you break down data silos and combine different types of analytics to gain insights and guide better business decisions.
Setting up and managing data lakes today involves a lot of manual, complicated, and time-consuming tasks. This work includes loading data from diverse sources, monitoring those data flows, setting up partitions, turning on encryption and managing keys, defining transformation jobs and monitoring their operation, re-organising data into a columnar format, deduplicating redundant data, and matching linked records. Once data has been loaded into the data lake, you need to grant fine-grained access to datasets, and audit access over time across a wide range of analytics and machine learning (ML) tools and services.
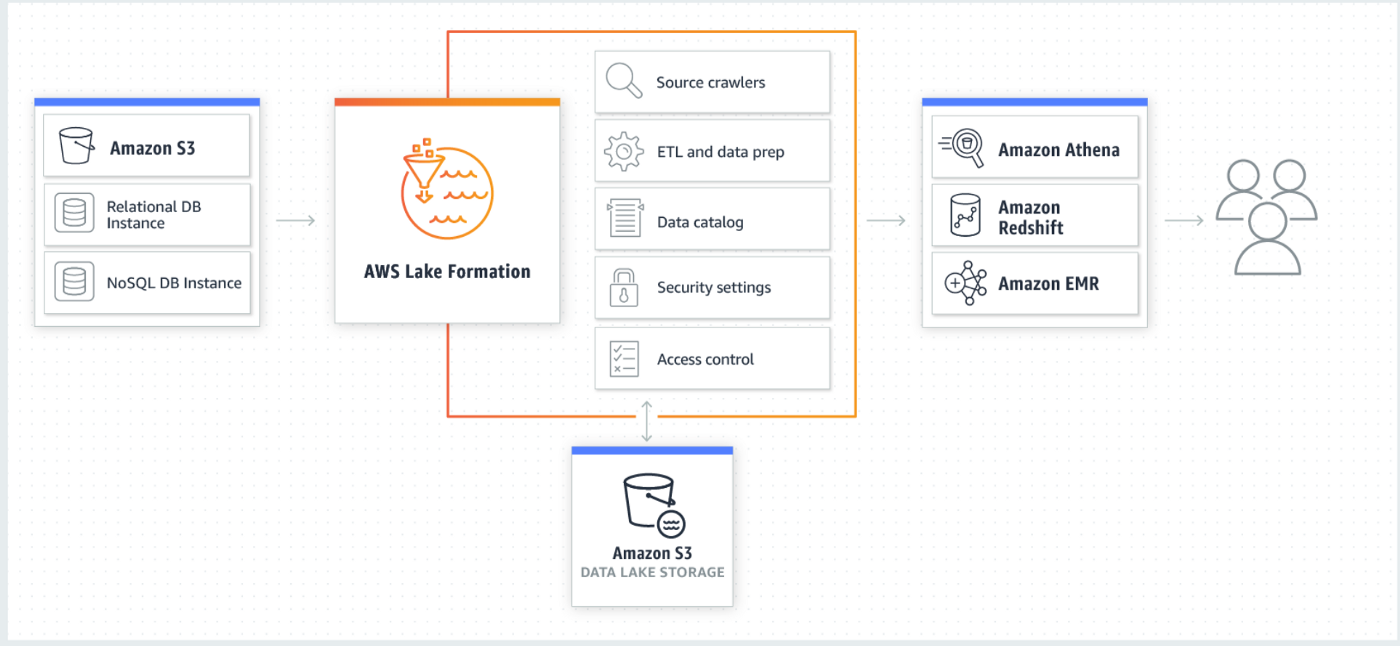
Creating a data lake with Lake Formation is as simple as defining data sources and what access and security policies you want to apply. Lake Formation then helps you collect and catalog data from databases and object storage, move the data into your new Amazon Simple Storage Service (S3) data lake, clean and classify your data using ML algorithms, and secure access to your sensitive data using granular controls at the column, row, and cell-levels. Your users can access a centralised data catalog that describes available datasets and their appropriate usage. They then use these datasets with their choice of analytics and ML services, such as Amazon Redshift, Amazon Athena, Amazon EMR for Apache Spark, and Amazon QuickSight. Lake Formation builds on the capabilities available in AWS Glue.
Benefits of AWS Lake Formation
Build data lakes quickly
With Lake Formation, you can move, store, catalog, and clean your data faster. You simply point Lake Formation at your data sources, and it crawls those sources and moves the data into your new Amazon S3 data lake. Lake Formation organises data in S3 around frequently used query terms and into right-sized chunks to increase efficiency. It also changes data into formats such as Apache Parquet and ORC for faster analytics. In addition, Lake Formation has built-in ML to deduplicate and find matching records (two entries that refer to the same thing) to increase data quality.
Simplify security management
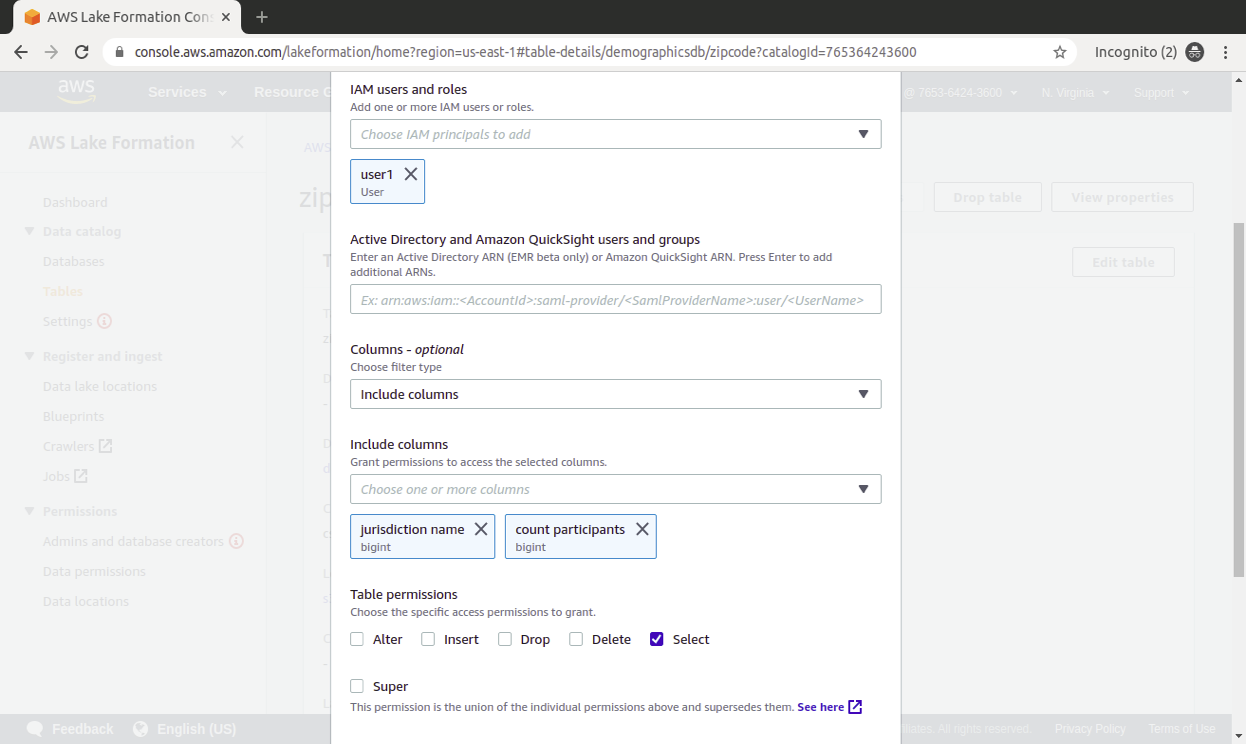
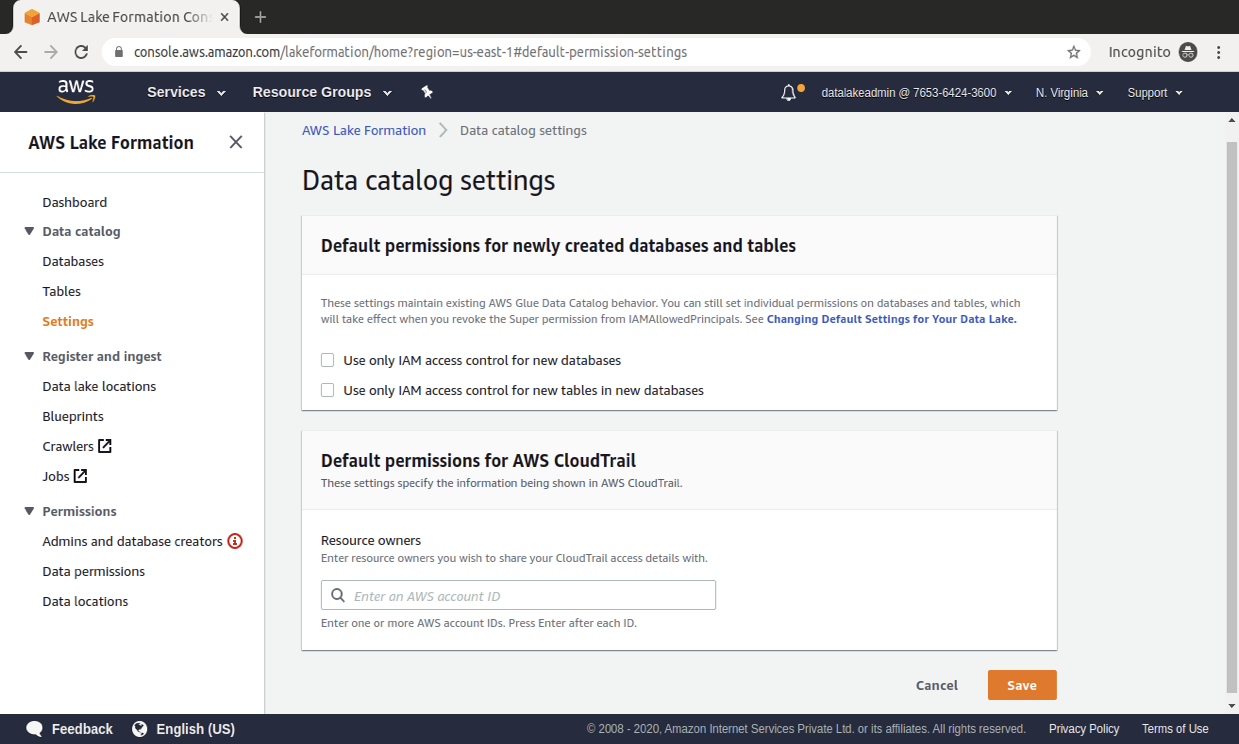
Lake Formation provides a single place to define and enforce access controls that operate at the table, column, row, and cell-level for all the users and services that access your data. Your policies are consistently implemented, eliminating the need to manually configure them across security services such as AWS Identity and Access Management (IAM) and AWS Key Management Service (KMS), storage services such as S3, and analytics and ML services such as Redshift, Athena, AWS Glue, and EMR for Apache Spark. This reduces the effort in configuring policies across services and provides consistent enforcement and compliance.
Provide self-service access to data
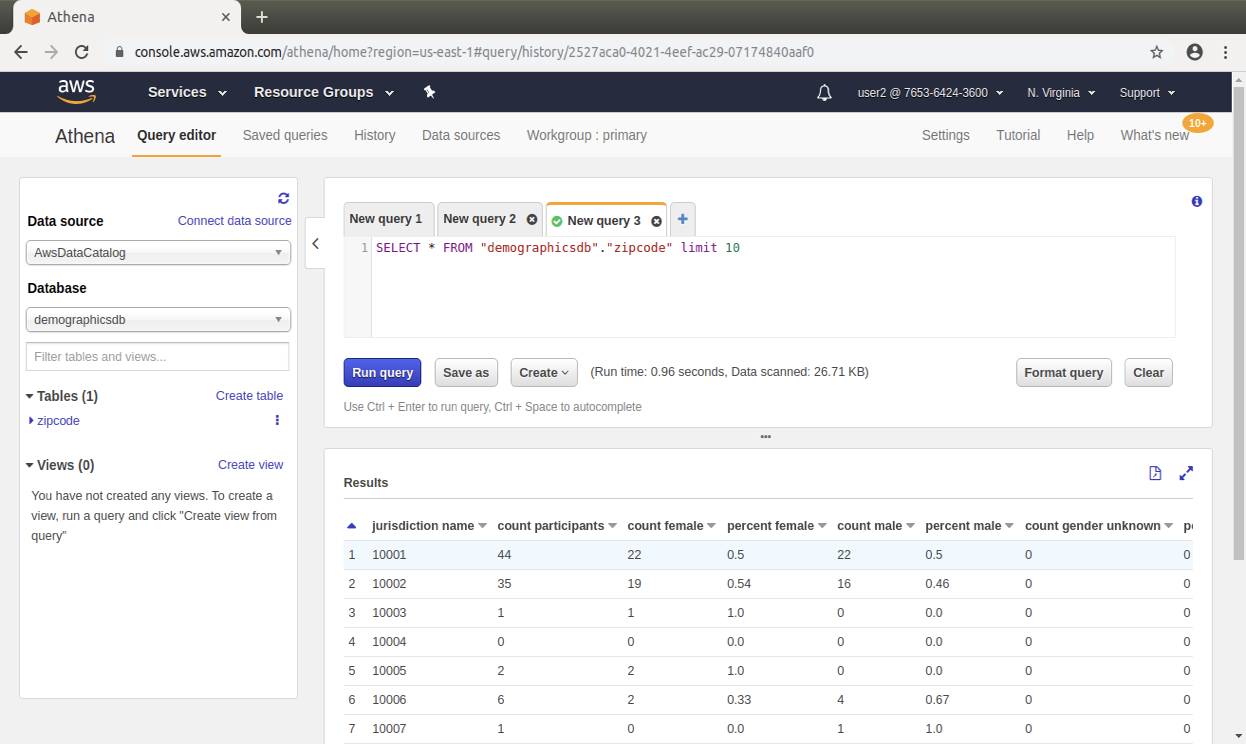
With Lake Formation, you build a data catalog that describes the different datasets available, along with which groups of users have access to each. This makes your users more productive by helping them find the right dataset to analyse. By providing a catalog of your data with consistent security enforcement, Lake Formation makes it easier for your analysts and data scientists to use their preferred analytics service. They can use EMR for Apache Spark, Redshift, Athena, AWS Glue, and Amazon QuickSight on diverse datasets now housed in a single data lake. Users can also combine these services without having to move data between silos.
Working of AWS Lake Formation
Lake Formation helps to build, secure, and manage your data lake. First, identify existing data stores in S3 or relational and NoSQL databases, and move the data into your data lake. Then crawl, catalog, and prepare the data for analytics. Next, provide your users with secure self-service access to the data through their choice of analytics services.