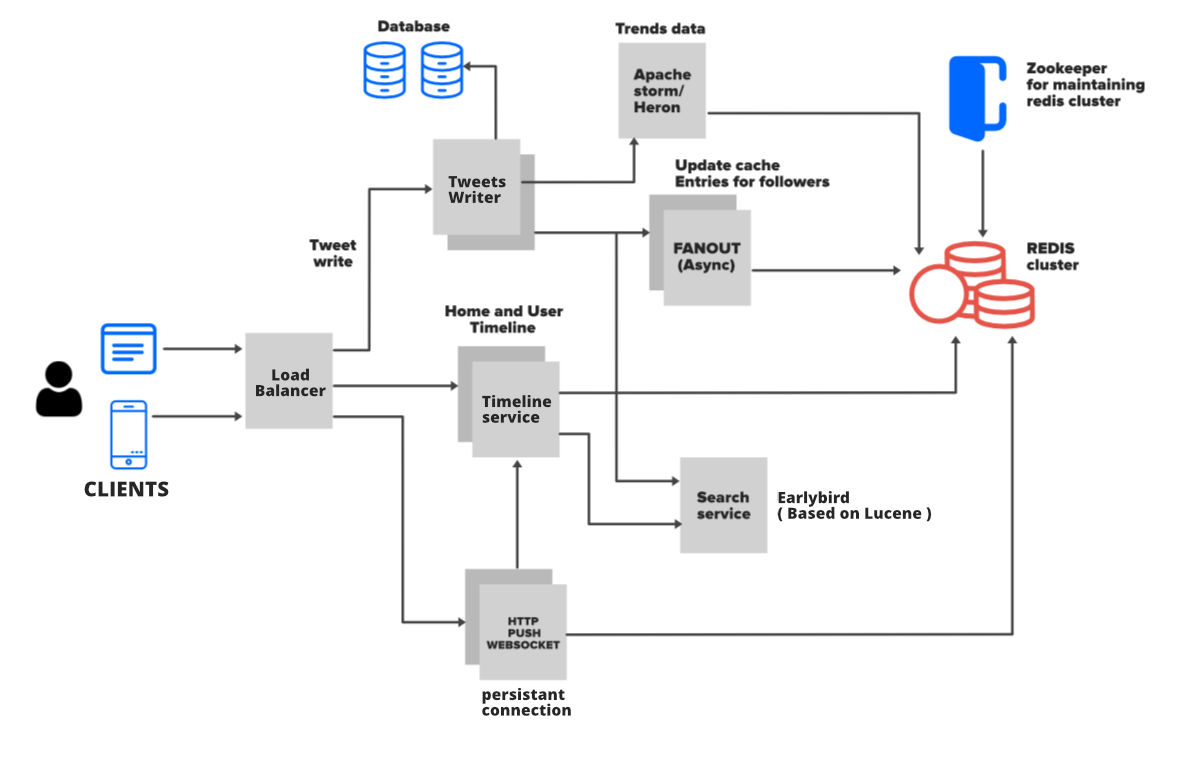
When I make a tweet, it is saved into the database, when a query is made the tweet is stored together with other tweets I made, the data is then pushed to all my followers' timelines.
The tweet is then updated to this person's homepage in the Redis list, and waiting for my followers to visit their home page. As soon as they do the tweet moves out from the list and is pushed to their timeline.
The list does not only contain my tweet but tweets of other people they follow who have tweeted before or after me, all these tweets are pushed to his timeline.
- The tweet flows from user to load balancer and from the load balancer to the writer API.
- From the API to the timeline services operator, which communicates directly with the Redis.
- The Redis then figures out appropriate timelines for users, this process is faster as it is in-memory.
- The Tweets are returned to the user timeline in JSON form.
Celebrity Tweets
How would the system handle tweets from a user such as Barack Obama or Elon Musk?
Barack Obama currently leads the way with 129 million followers, this means when he Tweets all his 129 million followers should have the tweet updated to their timeline.
When President Obama tweets it is saved into the database and added to the user timeline cache.
I am one of the followers of Pres. Obama inside my list his tweet and those of others I follow is stored.
Before all the data is pushed to my timeline, the algorithm checks how many celebrity accounts am I following, then moves on to check the cache of each celebrity and checks for recent tweets.
All celebrity tweets are added to my tweet list together with the average people I follow, these are all pushed to my timeline.
Trending Topics
Trending topics / # is measured using the following principle; the volume of tweets and time taken to generate the tweets.
Topics such as #Jeff Bezon and #Trump generate thousands of tweets in a short amount of time. This is compared to #AI which will generate a hundred thousand tweets over a year, hence #AI is not a trending topic.
A stream processing framework such as Apache Storm is used to determine # in real-time.