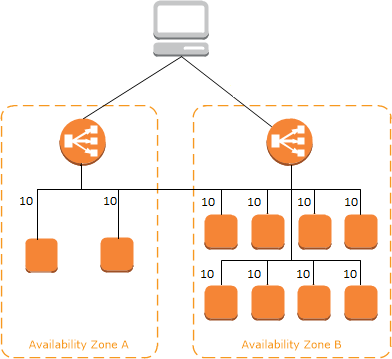
When a write is made, it is also replicated to the other master node then only an update will be sent for queries that have been made to the master.
Replicas for each and every node are made to handle the scalability and reliability of the RDBMS, these replicas are available locally and across data centers.
When one master node fails DNS configurations is made to redirect queries to the right master.
Cassandra
Apache Cassandra earned its reputation as an open source no sql schema-less database system that can handle large amounts of data.
Netflix adopted this data base management system to handle their big data, as Netflix grew data began to pile up and fill Cassandra nodes.
The ratio of user reads to writes became 9 to 1 prompting the engineering team at Netflix to optimize the database system.
A scheduled job system was developed which separated data into the following; live viewing history and compressed viewing history, with live viewing history being the most recent.
The scheduled jobs compressed the old viewing history which is kept until needed for whatever purpose, recent viewing history is used for building machine learning models.
Apache Kafka and Chukwa
Apache Chukwa is used for collecting logs from distributed systems, it comes from the Hadoop scalability and robustness.
All logs and events from different parts(Hysterix and inbound filter) within the system are sent to Chukwa.
This data is then visualized and analyzed with the build-in dashboard. Chukwa forwards the data to Amazon S3 and a copy of this data is sent to Apache Kafka.
The data is then routed with Kafkas routing service to various synchronized mechanisms such as Amazon S3, elastic search, and other secondary Kafka.
Elastic Search
The events and logs flow through Chukwa, Kafka and the final stop is elastic search.
There are about 150 clusters and 3500 instances that handle elastic search on the AWS backend.
Practical use case of elastic search would be streaming errors experienced by clients; customer service can just search for the error using the customer's details and the error will be visualized, together with details of the error.
Elastic search can also be used to visualize; Sign up, login and keep track of usage.
See Also:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html
https://www.loginworks.com/blogs/how-netflix-use-data-to-win-the-race/
https://github.com/Netflix/Hystrix
https://github.com/Netflix/zuul