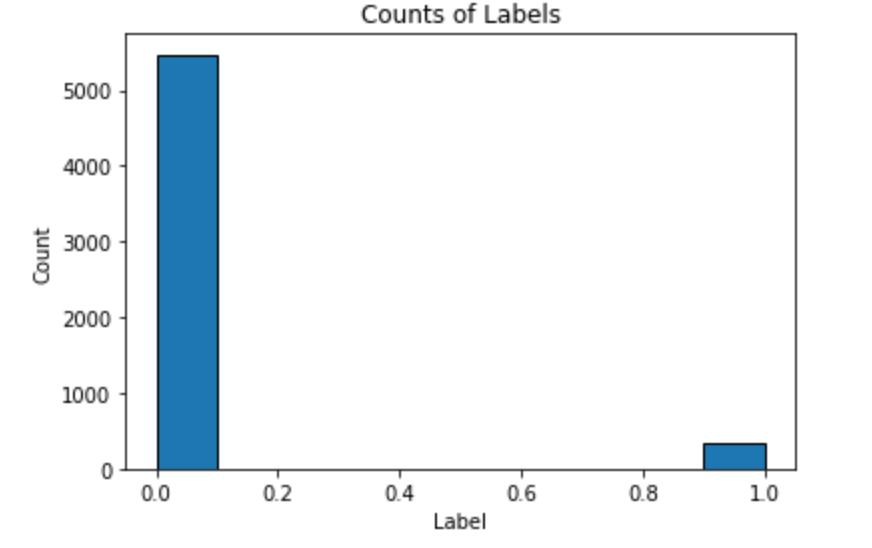
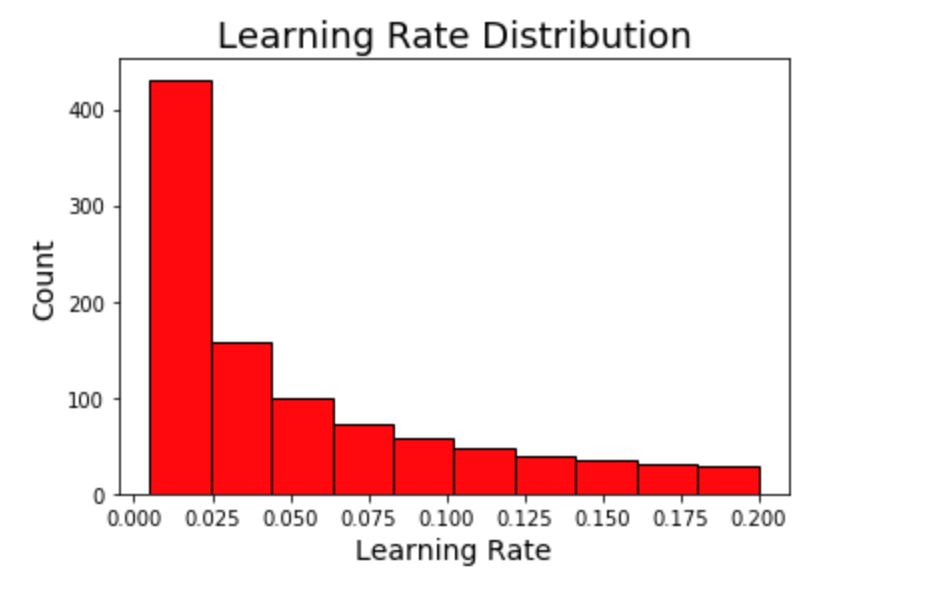
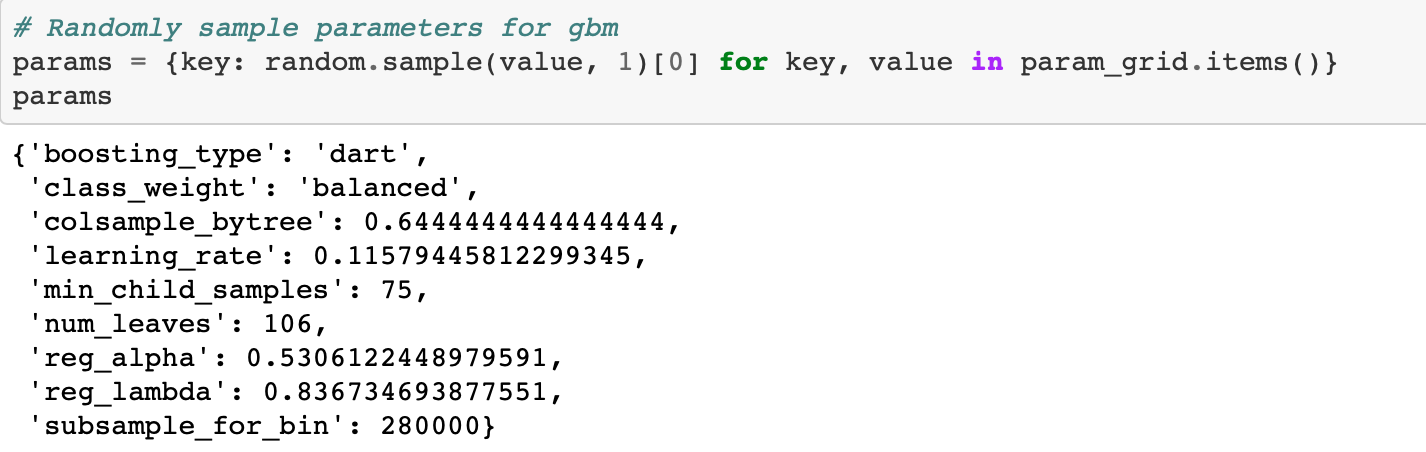
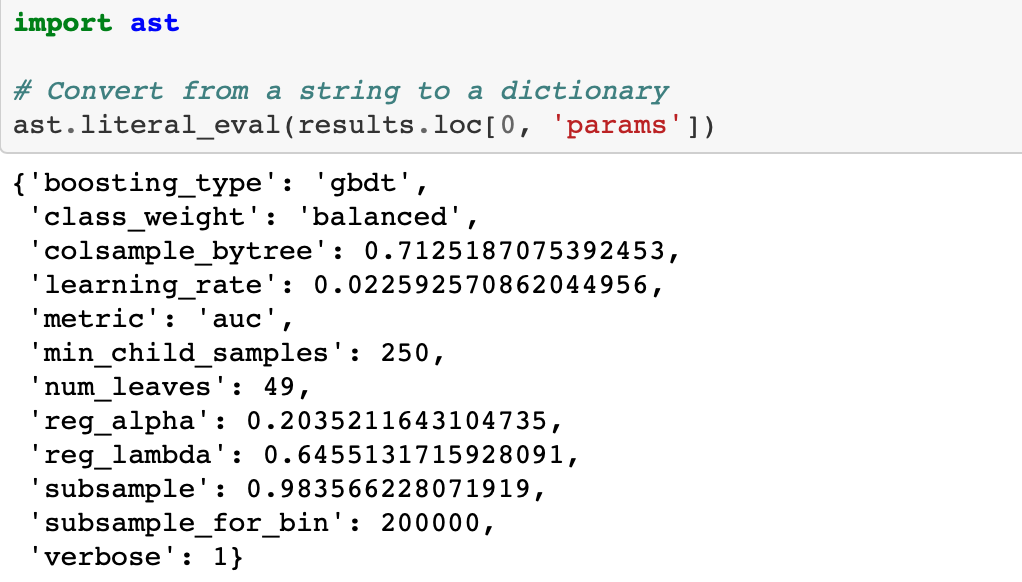
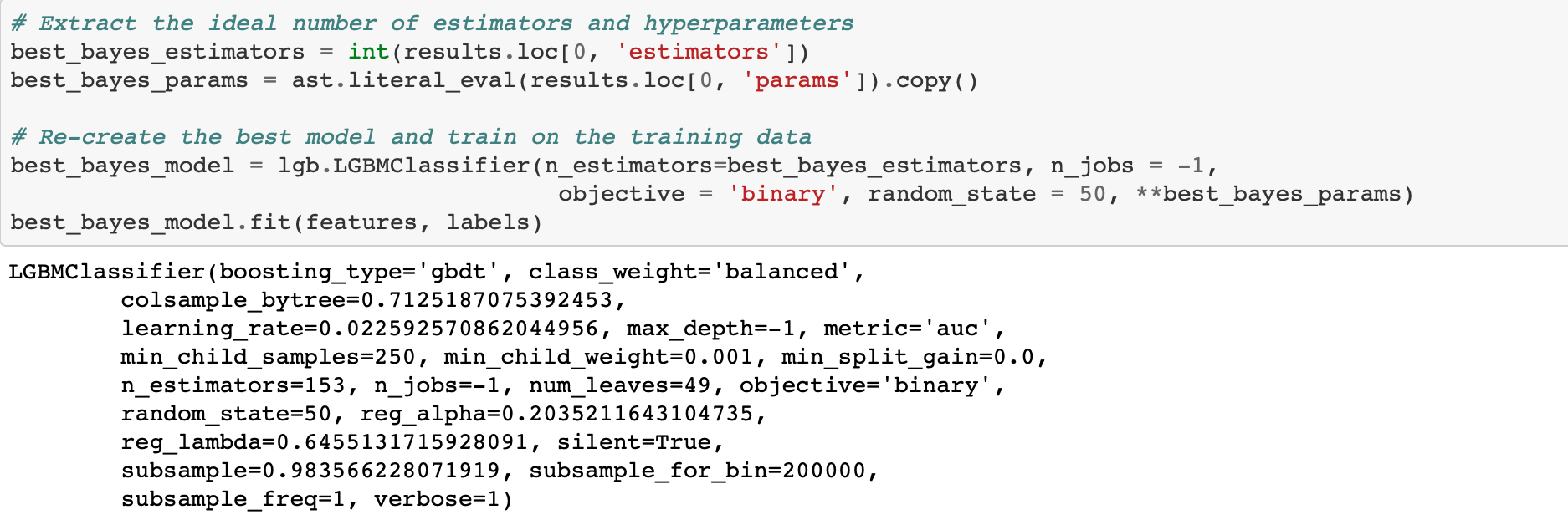
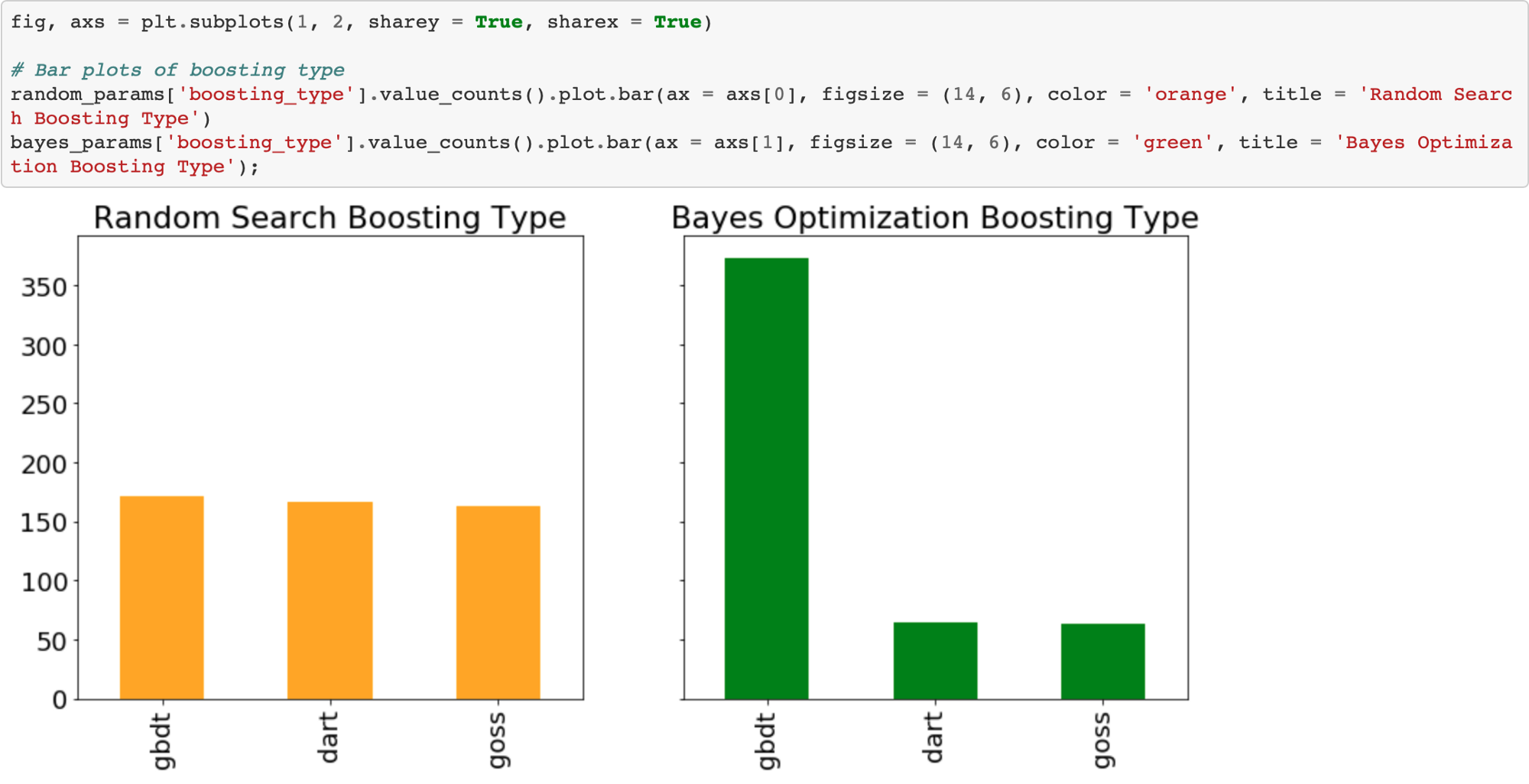
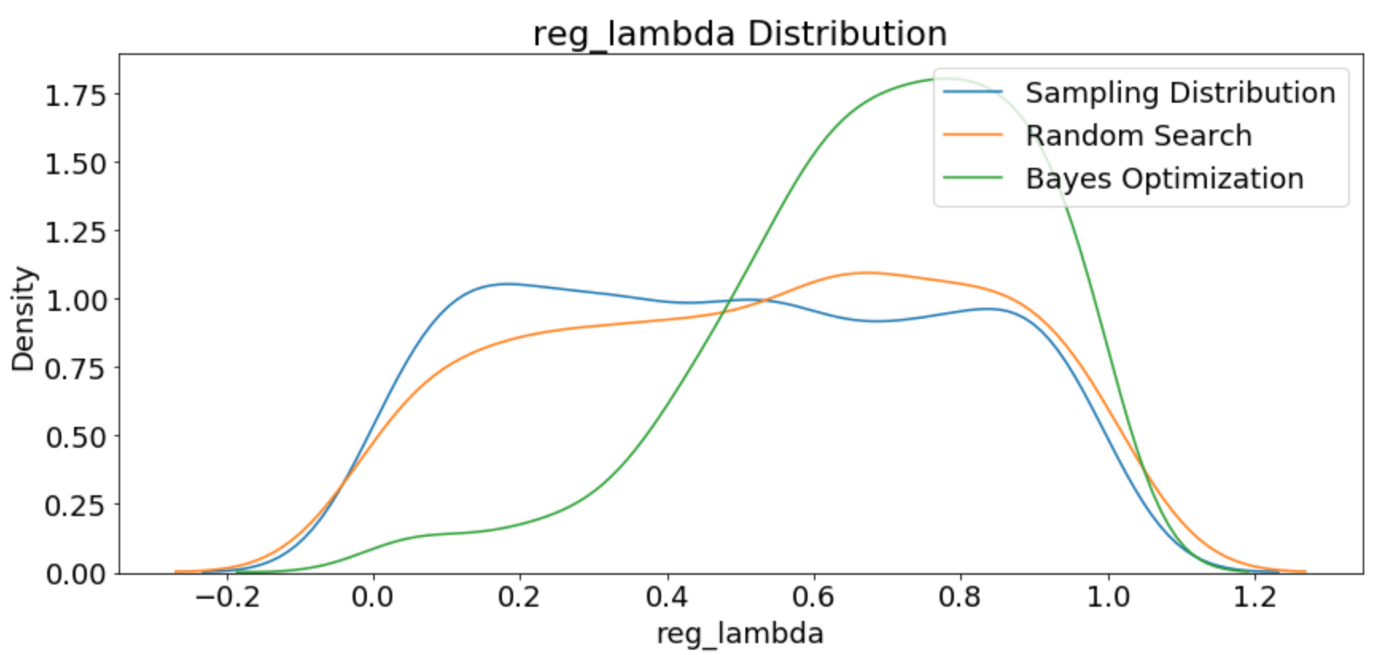
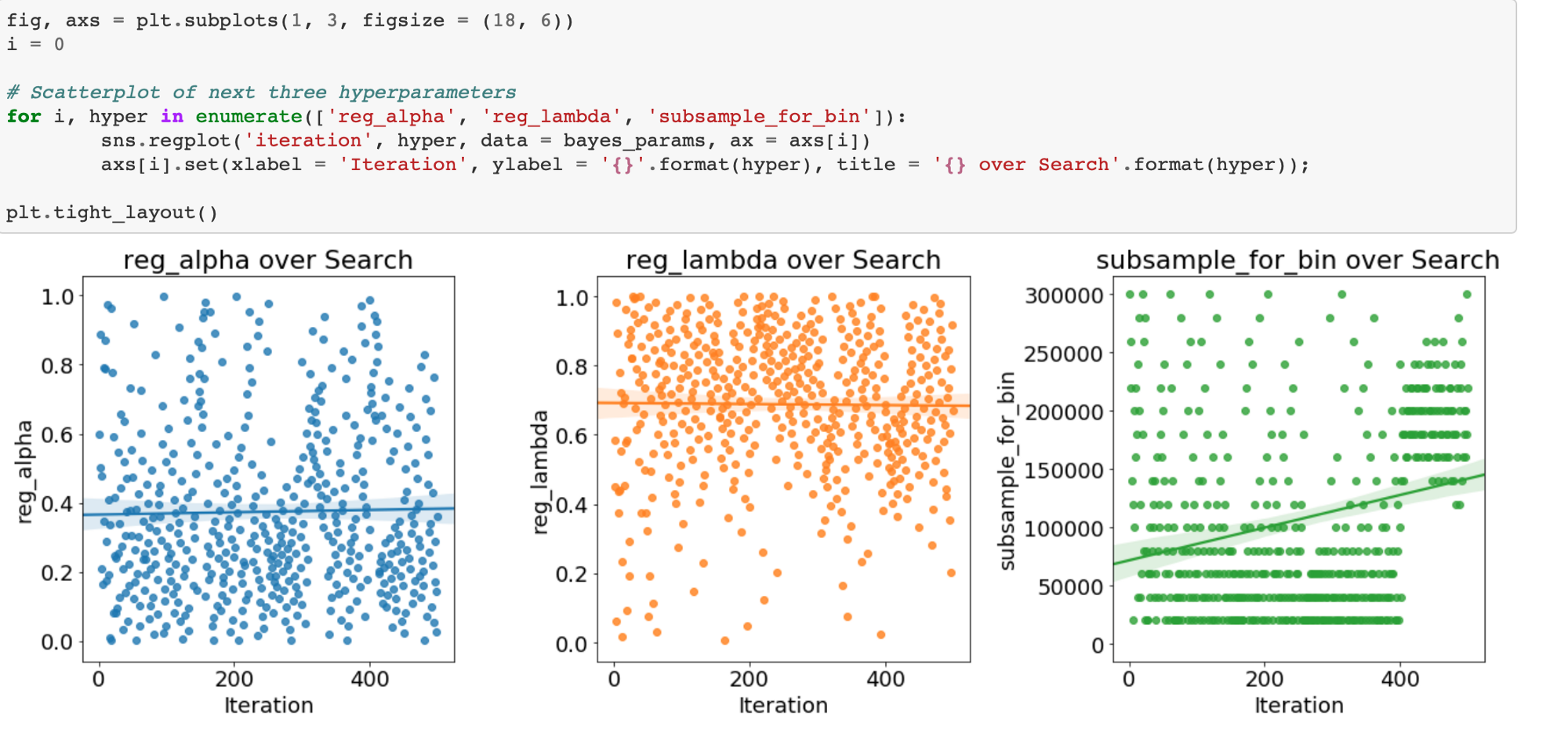
A modest gain over the baseline. Using more evaluations might increase the score, but at the cost of more optimization time. We also have to remember that the hyperparameters are optimized on the validation data whigh may not translate to the testing data.
Now, we can move on to Bayesian methods and see if they are able to achieve better results.
Bayesian Hyperparameter Optimization using Hyperopt
For Bayesian optimization, we need the following four parts:
- Objective function
- Domain space
- Hyperparameter optimization algorithm
- History of results
We already used all of these in random search, but for Hyperopt we will have to make a few changes.
Objective Function
This objective function will still take in the hyperparameters but it will return not a list but a dictionary. The only requirement for an objective function in Hyperopt is that it has a key in the return dictionary called "loss" to minimize and a key called "status" indicating if the evaluation was successful.
If we want to keep track of the number of iterations, we can declare a global variables called ITERATION that is incremented every time the function is called. In addition to returning comprehensive results, every time the function is evaluated, we will write the results to a new line of a csv file. This can be useful for extremely long evaluations if we want to check on the progress (this might not be the most elegant solution, but it's better than printing to the console because our results will be saved!)
The most important part of this function is that now we need to return a value to minimize and not the raw ROC AUC. We are trying to find the best value of the objective function, and even though a higher ROC AUC is better, Hyperopt works to minimize a function. Therefore, a simple solution is to return 1 — ROC (we did this for random search as well for practice).
Although Hyperopt only needs the loss, it's a good idea to track other metrics so we can inspect the results. Later we can compare the sequence of searches to that from random search which will help us understand how the method works.
Domain Space
Specifying the domain (called the space in Hyperopt) is a little trickier than in grid search. In Hyperopt, and other Bayesian optimization frameworks, the domian is not a discrete grid but instead has probability distributions for each hyperparameter. For each hyperparameter, we will use the same limits as with the grid, but instead of being defined at each point, the domain represents probabilities for each hyperparameter. This will probably become clearer in the code and the images.