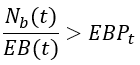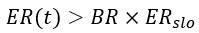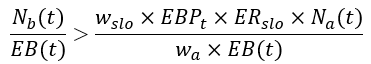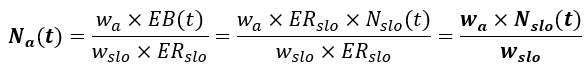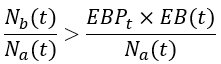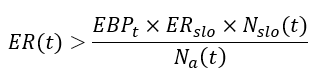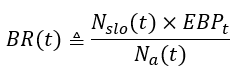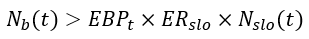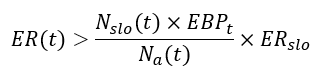While my proposed solution was simply to alert on the error budget instead of the error rate, in this part I will show how we can still alert on the error rate but do it correctly. More importantly, the novel error-rate-based alert I will develop will expose a dynamic time-dependent burn rate expression which in contrast to Google’s static one leads to built-in compatibility to varying-traffic services.
Motivation
A certain disadvantage in my proposed solution in part 1 is that the metric which it alert on is the error budget while the metrics we care for when implementing SRE are the SLIs (or the actual error rate) and the percentage of error budget consumption. Hence, alerting on the error budget might not be consistent with our SLO and percentage of error budget consumption dashboards.
Again, the solution for this is quite easy. Eventually, the alert rule is just inequality between the actual number of bad requests in the alerting time window to some multiple of the error budget (defined by the percentage of error budget consumption that we want to alert on). If we divide this inequality by the total number of requests in the alerting time window we will get the desired inequality rule for an error-rate-based alert.
But, wait… isn’t it what Google did in the first place? Why do we need to go back and forth from error budget to error rate? To answer these questions, I’ll show in the following how Google’s formulation of static burn rate inevitably leads to an overly strict assumption on the traffic profile that doesn’t hold for varying-traffic services and how a correct transformation from the error budget domain to the error rate one leads to the more generalized form of time-dependent burn rate which is compatible with all traffic profiles.
Notations
To ease with the mathematical formulations let us define the following notations:
- wₐ - Alert time window (for example 1h, 6 h, etc.)
- w_slo - SLO period (7 days, 28 days, etc.)
- Nₐ(t) - Total number of events in the alert time window, wₐ
- Nb(t) - Total number of bad events in the alert time window, wₐ
- N_slo(t) - Total number of events in the SLO period, w_slo
- EB(t) - Error budget. The allowable number of bad events for the SLO period, w_slo
- EBP_t - The percentage of error budget consumption used as a threshold for alerting
- SLO - The SLO defined on the SLO period, w_slo. expressed as fraction (0.99, 0.999, etc.)
- ER_slo - The allowable error rate for the SLO window, w_slo: 1-SLO
- ER(t) - The actual error rate calculated on the alert time window, wₐ: