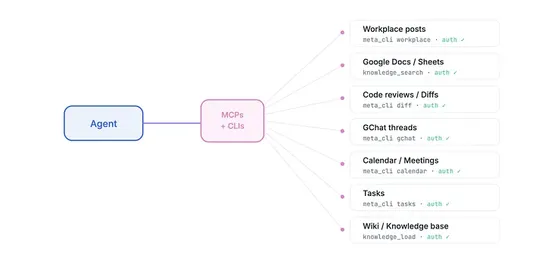
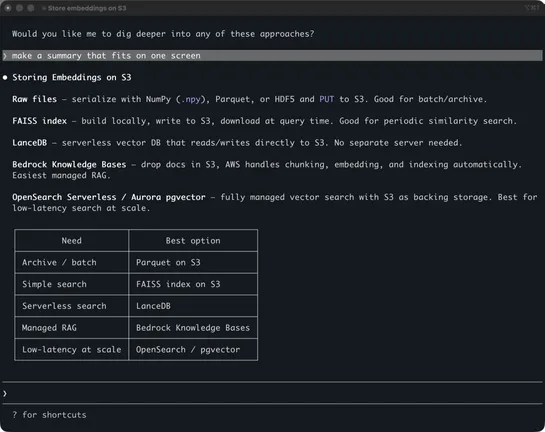
Slop Creep: The Great Enshittification of Software
The argument is that coding agents accelerate codebase decay by removing the natural speed limit on bad architectural decisions, compressing months of compounding mistakes into days. The defense is to invest ten times more in the planning phase, with concrete code snippets for the data models and ab.. read more