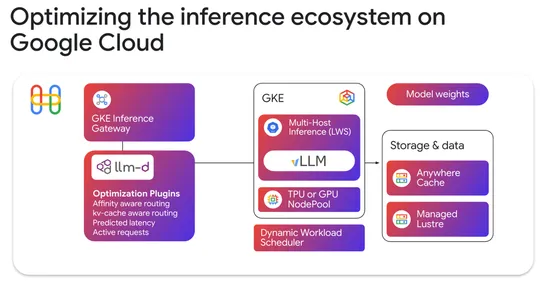
llm-d officially a CNCF Sandbox project
At Google Cloud, the llm-d project has been accepted as a Cloud Native Computing Foundation (CNCF) Sandbox project. This collaboration with industry leaders like Red Hat, IBM Research, CoreWeave, and NVIDIA aims to provide a framework for any model, accelerator, or cloud. The introduction of GKE Inf.. read more