Chinese Vulnerability Database: CNVD vs CNNVD Analysis
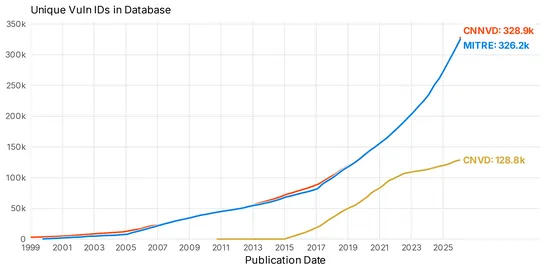
Investigation profilesCNNVDandCNVDechoCVE. They reveal manual errors and poor machine-readability. China’s July 2021RMSVmandates 48-hour reporting and bans pre-patch disclosure. Mapping gaps exist. The databases published about1.4kentries ahead ofCVE, with lead times measured in months... read more