Trivy Hack Spreads Infostealer via Docker, Triggers Worm and Kubernetes Wiper
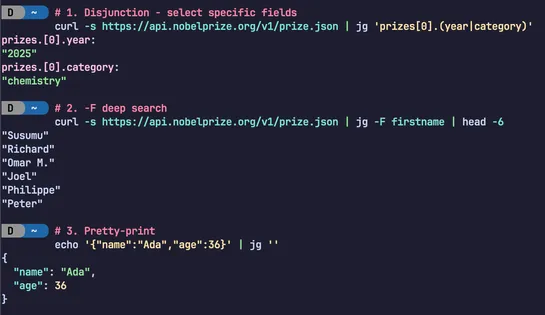
Cybersecurity researchers found malicious artifacts distributed via Docker Hub after the Trivy supply chain attack. Malicious versions 0.69.4, 0.69.5, and 0.69.6 of Trivy were removed from the image library. Threat actor TeamPCP targeted Aqua Security's GitHub organization, compromising 44 repositor.. read more