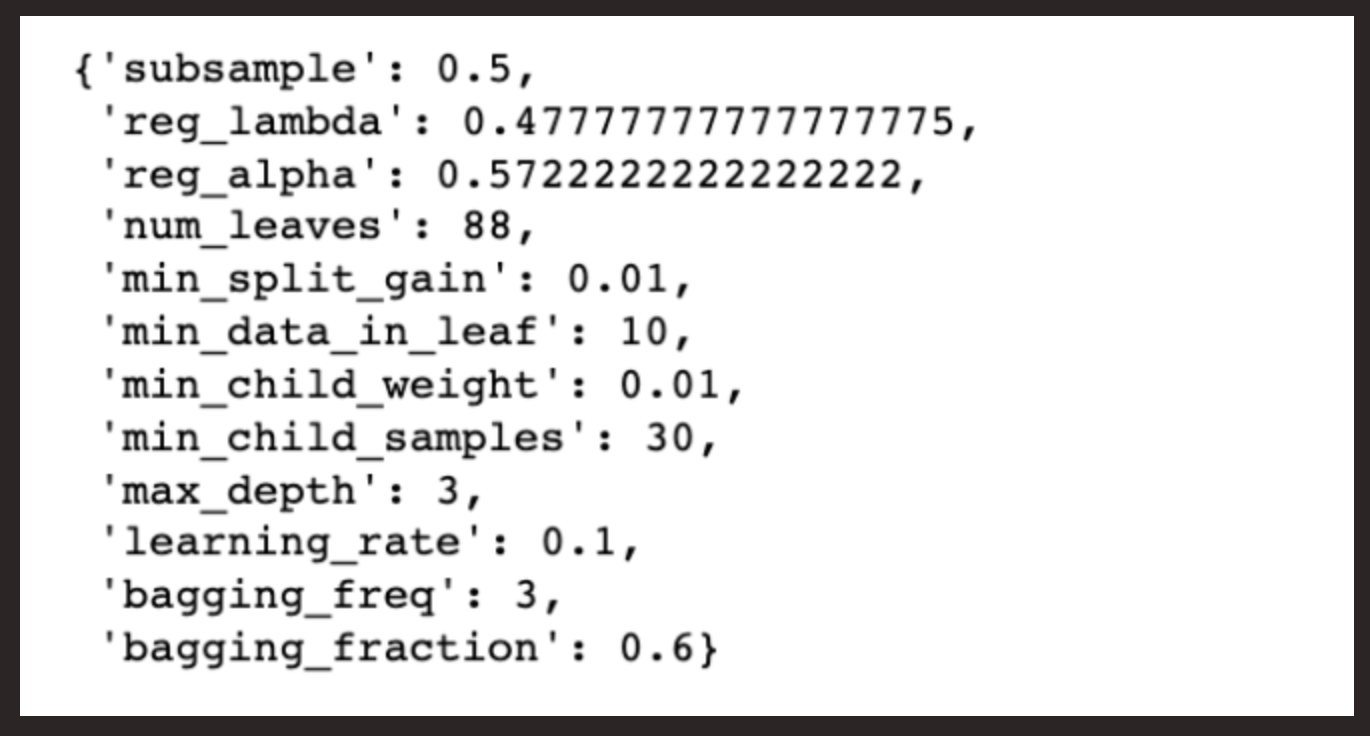
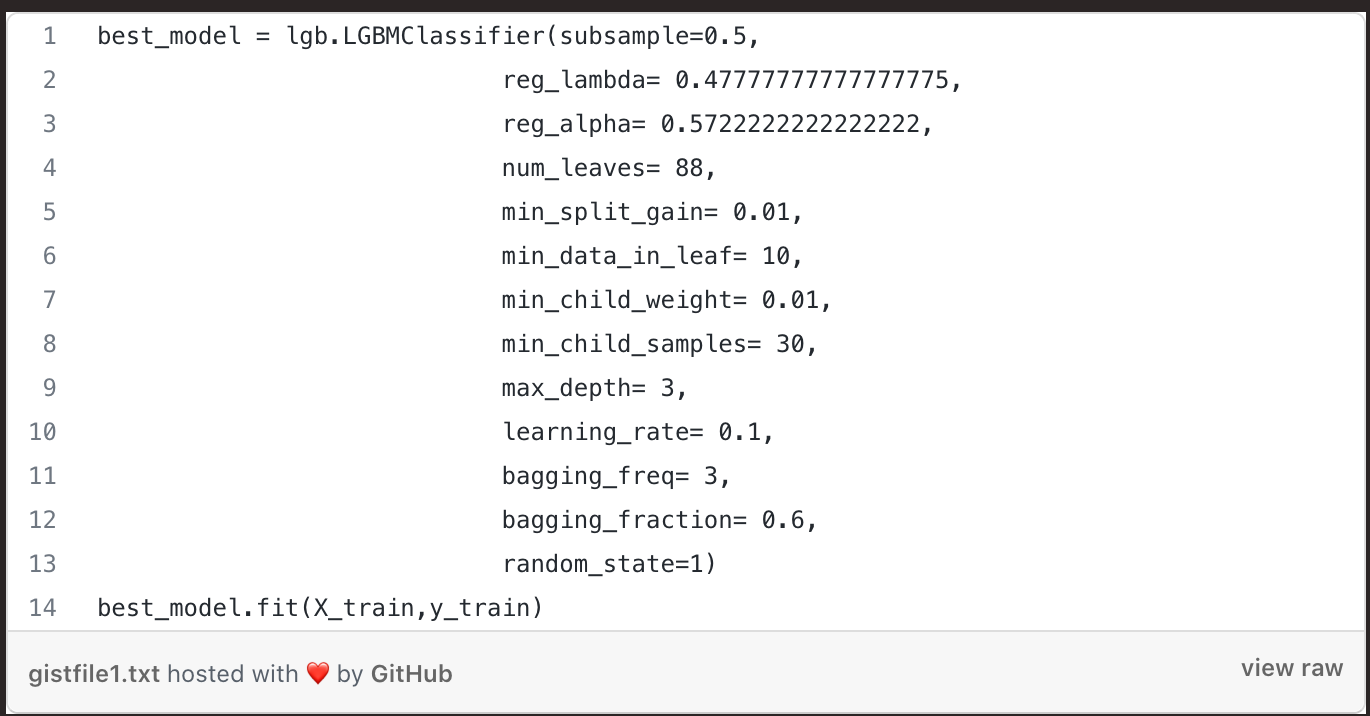
We will work with the Agora messaging API so that you’ll be able to classify SMS messages sent to the phone number you have in your Agora account.
Prerequisites
In order to follow and fully understand this tutorial, you’ll need:
- Python 3.6 or newer. The Anaconda distribution includes a number of useful libraries for data science.
- A basic knowledge of Flask, HTML, and CSS.
- A basic understanding of building machine learning models.
- Agora free virtual number.
AGORA API ACCOUNT
To complete this tutorial, you will need an Agora API account. If you don’t have one already, you can sign up today and start building. Once you have an account, you can find your API Key and API Secret at the top of the Agora API Dashboard.
This tutorial also uses a virtual phone number. To get one, go to numbers and search for one that meets your needs.