There are hundreds of articles and videos about it, but not many talks about its building blocks. They would be overly articulating about the usage and commands. Even if you go through the official documentation, you can only get the hang of usage but not the internals. Internals are fun to know and it will boost your confidence while you use the product. So in PART 1, I explain the internals in simple terms as usual. Let me see if I can do it.
GIT is Distributed Version Control System — What that means?
The creator of GIT is none other than Linus Torvalds. Hope you know his first product, the “LINUX Kernel” which is ruling the world. What else do you expect out of him? Just one more product to rule the world.
And first thing first! Git is just a “stupid content tracking tool” as expressed by the creator himself. How it was made as a “Distributed Version Control System” is sheer brilliance. It means, it does the following:
- It tracks the different versions of the evolution of a file.
- If needed, it allows us to get back to a particular version quickly.
- Tracking back and forth is not just for a single file but for the entire repository as a revision.(*After all, the entire repository is just Trees and blobs).
- You don’t have to connect to a server for switching between versions/revisions.
- All the above-mentioned works in a distributed way i.e., everything is brought in your local system. The server contents are a mere copy of what you have locally.
Centralized Vs Distributed
In a centralized repository, multiple versions of files is maintained in a central server. When people sync for the recent changes at some point, it downloads the very recent snapshot from the server. Later, if you want to go to any other previous version, you can fetch that from Central Server and replace it locally with the one you have. That means, at any point in time, just only one snapshot is present in your local machine.
In contrast, once you clone/pull, Git stores everything in its entirety in your local storage. Let’s assume you have 20 released versions of your repository, Git stores all those 20 snapshots in your local system and you can go back and forth without connecting to any server. I know you might be asking me like — “Wait! Let’s say my repo size is 5 GB and it stores 20 versions of it in my local repository, so it sweeps off 5*20 = 100 GB of my disc space?”. Actually no! That’s the beauty of Git. How Git stores and visualizes files really matters and that unique mechanism gives the power of distributed nature of it.
Hash & DAG — Keep these in mind.
Before getting into the Git object model, you must know the following about Hash:
- Hashing is different from encryption and it is one way i.e, you cannot get the hashed content back with the help of hash.
- Hashing is a mechanism of producing “digest” for a given stream of characters.
- A digest is a unique standard size of bits.
- SHA-1 used in GIT is one of the famous Hashing mechanisms, which produces 160 bits of “digest” for any stream of characters as input.
- A “digest” is usually represented in Hexadecimal values (4 bits), thus an SHA-1 digest would look like 40 (160/4) hexadecimal characters.
- There is no size or word limitation on the input stream of characters.
- A trillion characters content or a single character content, both result in a Hash of the same size i.e., 40 Hex Characters.
- Hash keys produced by SHA-1 are unique and it is humanly impossible to collide for 2 different contents. Let’s not debate on that.
Another concept to remember is DAG. DAG (“Directed Acyclic Graph”) is one type of graph representation without cycles. Tracking evolution is one of its use cases.
Git’s Object Model — Quick glance
On your git repository, you will obviously see the current working snapshot of your files. The rest all files of the multiple snapshots of your repository would be consolidated and represented in a hidden directory called “.git”.
Let me give a very quick overview of “.git" storage structure straight away.
- Each Unique file (I mean the file contents) would be hash computed by Git.
- If 2 or more files have “ditto” the same contents in your repository, then only one hash is computed.
- The hash “digest” is the file name in “.git” and actual file contents will be compressed inside that file.
- Every file of your repository is constructed like above when “added” to the git.
- When you “commit” those changes (Let’s say C1), it will create a new commit index using its contents (commit text+username+timestamp+etc) as a new special hash object. Thus, it MUST be unique.
- This special hash object (commit hash) will be connected to all those file content hashes like a DAG.
- Later, whenever a file is changed and “added”, GIT creates a new hash file “only” for that file object.
- When “committed” again (Let’s say C2), it will create a committed index connecting to that changed file. For the rest of the file objects, it connects them using a pointer to that sub-part of DAG.
- Git visualizes the whole repository’s file system in its own style and stores them as commits, blobs (file contents), and trees with connections.
All those mentioned are consolidated in that hidden “.git” directory present in your repository as I mentioned. That’s it! That’s the whole product. As I promised, I will not go further and this level of understanding is good enough to work with the product.
Some important “Reference Pointers” of GIT
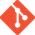
Now we learned, if we just track the “commit” index, we can easily reconstruct a sub-tree of your DAG and that is your revision. How would you track it? It is again simple! Just with reference pointers. A reference pointer tracking a committed index is called “branch”. You can create as many branches as you can like “JIRA-123”, “stupidIdea”, “RTC-567” etc.
Irrespective of you creating a reference pointer, 2 reference pointers that you must know is HEAD & master. You are free to rename “master” as “main”, “development”, “virgin” or whatever. But “HEAD” remains “HEAD”.
master — It is a reference to the latest commit in the repository. This is also the first branch of a repository created by the git itself. Thus, it keeps tracking the latest snapshot in the repository.
HEAD — This is a “movable” reference pointer to a reference pointer. Mostly, it would be referencing “master” branch until switched. When “switch/checkout” is called, it will reference that particular branch.
In the below diagram, I have abstracted commit as single entity (it will be pointing to multiple blobs and trees internally) to illustrate how master and HEAD moves.