Before exploring Kubernetes volumes, let’s first understand Docker. Docker containers are meant to be transient, which means they will only last for a short period. They are called upon when required to process data and are destroyed once finished.
The same is true for the data within the container. The data is destroyed along with the container. To persist data processed by the container, we attach a volume to the containers created. Now even if the container is deleted, the data generated or processed by it remains.
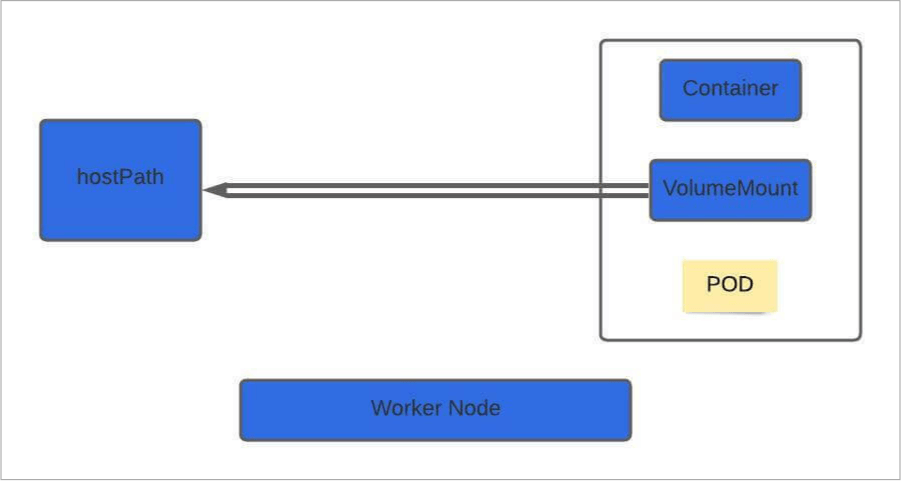
Now let’s look at how it works in the case of Kubernetes. In Kubernetes, when a pod is created to process data and then deleted, the data processed by it gets deleted as well. Kubernetes offers many storage components to prevent this data loss. These components are Volume, Persistent Volume, Persistent Volume Claim, and Storage Class. In this blog, we will learn how Volume works in Kubernetes, how to create it, and how to attach it to the Pod.