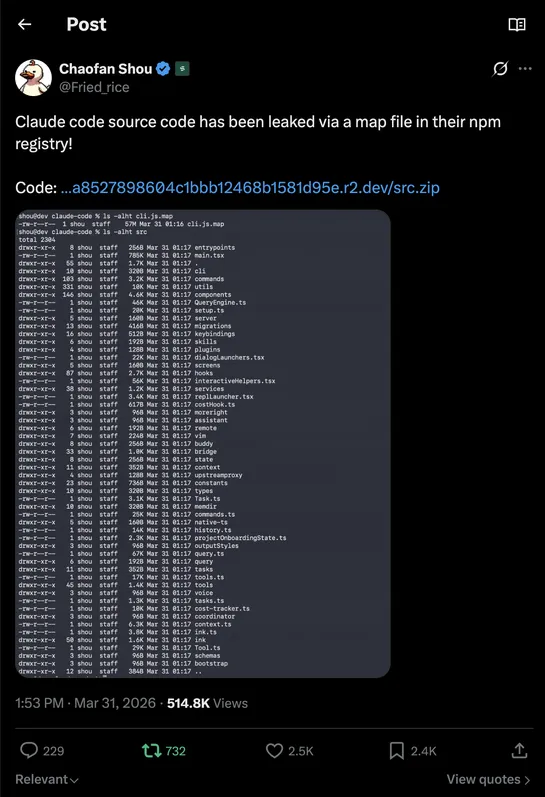
Anthropic Accidentally Leaks Claude Code's Entire Source Code via npm

Anthropic shipped a source map file inside the latest npm release of Claude Code - and with it, the full source code of its flagship AI coding CLI. The leak exposed 512,000 lines of TypeScript across 1,900 files, 43 built-in tools, 44 feature flags, 26 hidden slash commands, and over 120 secret environment variables. It is one of the most detailed accidental exposures of a commercial AI product's internals to date.