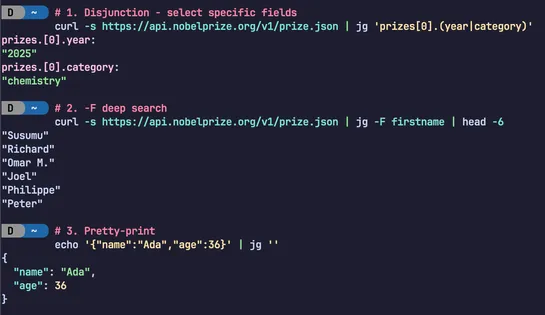
jsongrep is faster than {jq, jmespath, jsonpath-rust, jql}
This article introduces a tool called jsongrep, explains the internal search engine it uses, and outlines the benchmarking strategy used to compare its performance with other JSON path-like query tools. The tool parses the JSON document, constructs an NFA from the query, determinizes the NFA into a .. read more