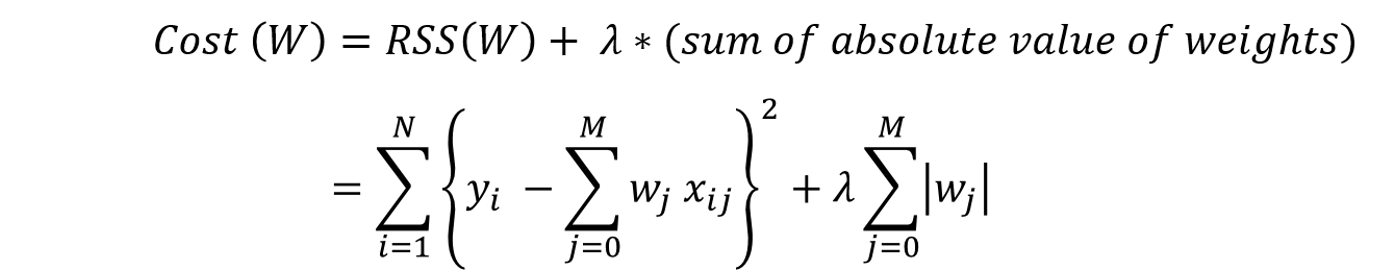Now, from the model, you come to notice that it has Overfit — Overfitting is a term used in data science to describe when a statistical model fits its training data perfectly and the algorithm is unable to perform accurately against unknown data, negating the goal of the method. Now this Overfitting could be because the model is too complex. This complexity will have to be reduced to improve the model and remove Overfitting.
To do this we can either decrease the magnitude of some of the Regression Coefficients and/or we could drop some of the features that do not add significant value to the final prediction. The process we will be applying to achieve this is called Regularization.
So we have come to the end of this article. Thank you.
Lol, just kidding. Well, that’s how most articles on this topic go anyway. But trust me, this one is going to be different. Let me take you through the complete experience — starting with understanding why and where we need it, its statistical importance and also how we implement it on Python.
Understanding Bias and Variance
Let us get to the basics once more — Bias and Variance.
We say that a model’s Bias is high when the model performs poorly on the training dataset. The Variance is said to be high when the model performs poorly on the test dataset. Let me give you an example to make it more clear.
Scenario 1: