We’re referring to the framework used for tabular analysis. The name is derived from “panel data” a term closely associated with multidimensional structured data sets.
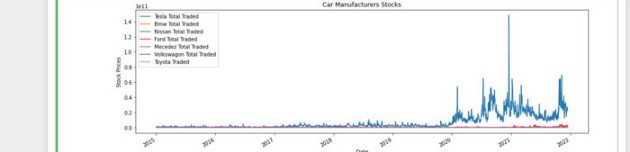
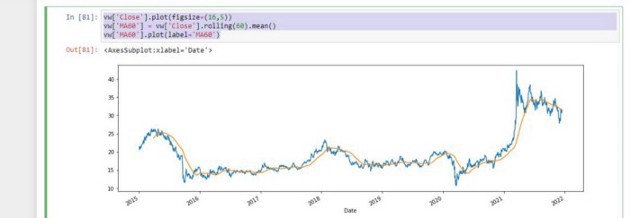
I have thought of an interesting use case for Pandas and that is stock market analysis.
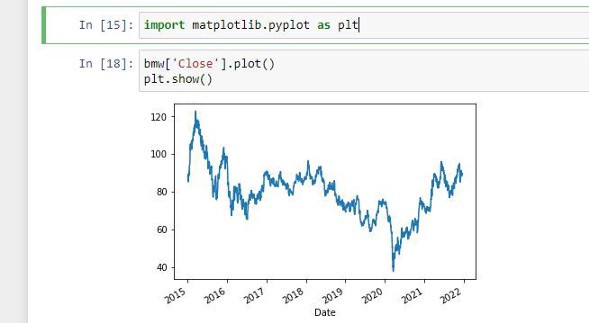
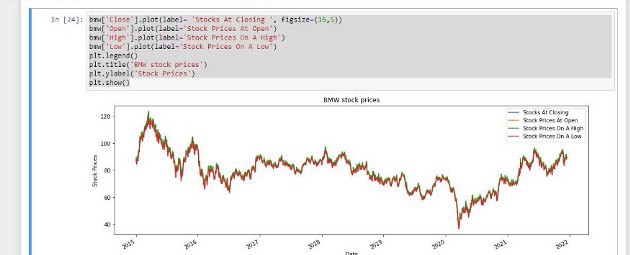
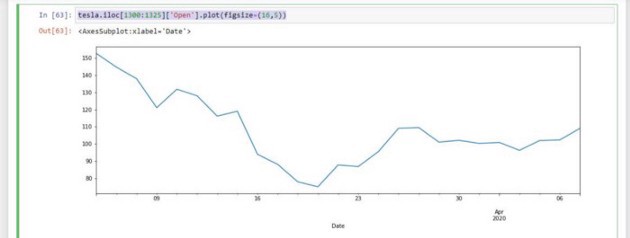
We want to analyze the stock prices of my 5 favorite car manufactures, and see all the interesting cool things we can do with Pandas.
Setting Up Our Environment
Before diving into any project it is important to have our toolbox ready, this is mainly setting up the environment.
We will create a folder and we will name ours ‘Analysing_Stock_Prices’, open our Anaconda prompt as an administrator and cd into the folder ‘Analysing_Stock_Prices’, and open the Jupyter Notebook.