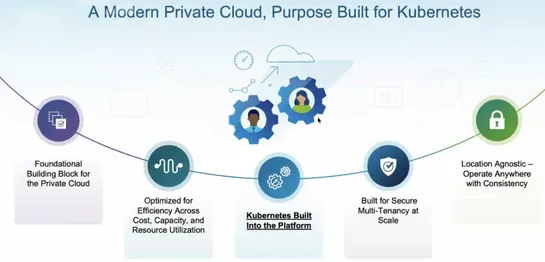
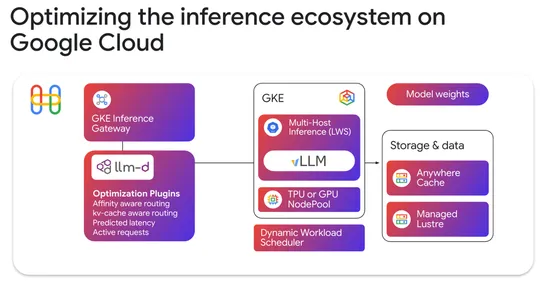
Kubernetes v1.36 Sneak Peek
Kubernetes v1.36, coming inApril 2026, will feature removals and deprecations, with enhancements that include retirement of the Ingress NGINX project and thedeprecation of .spec.externalIPs in Service.Additionally, the release will remove the gitRepo volume driver and introduce enhancements like fas.. read more